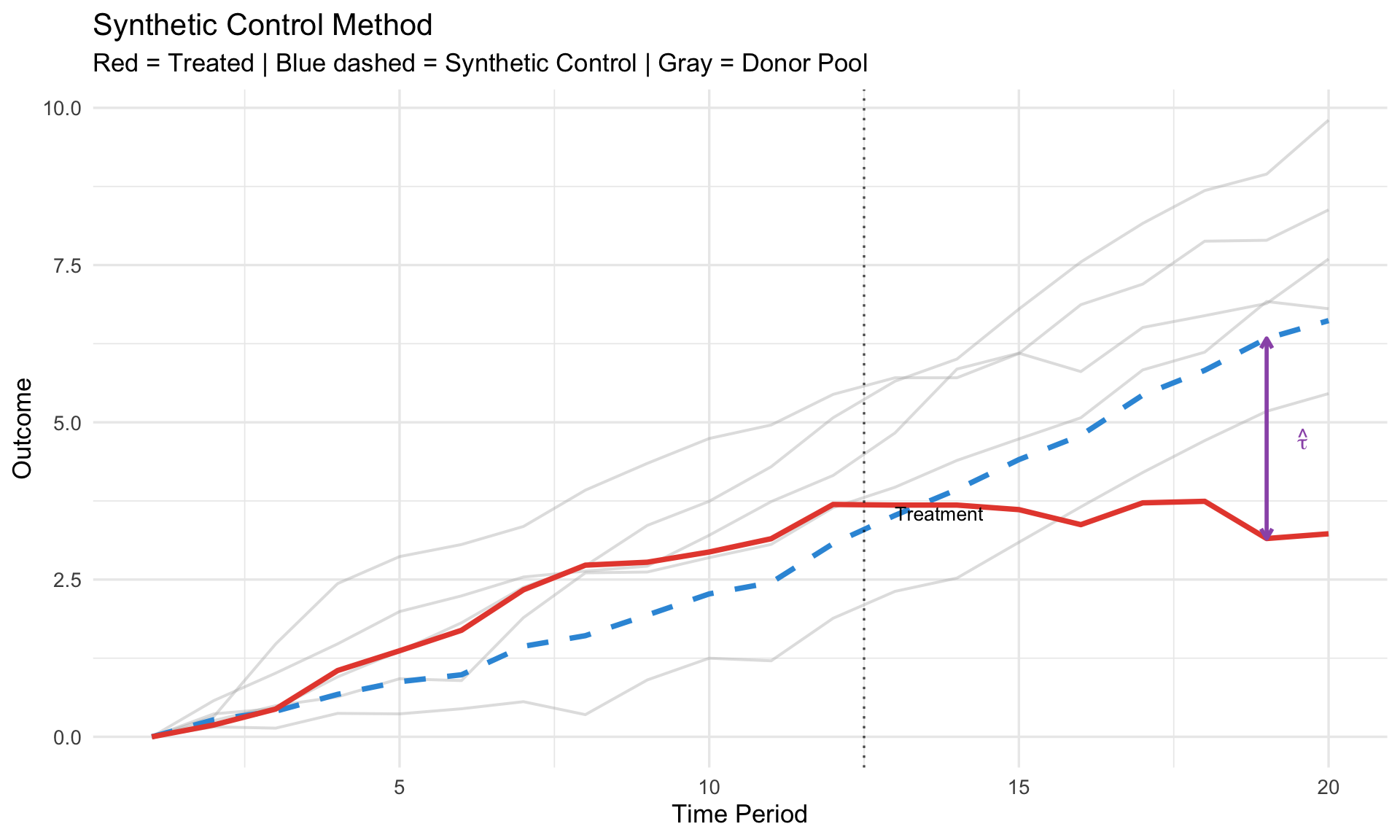
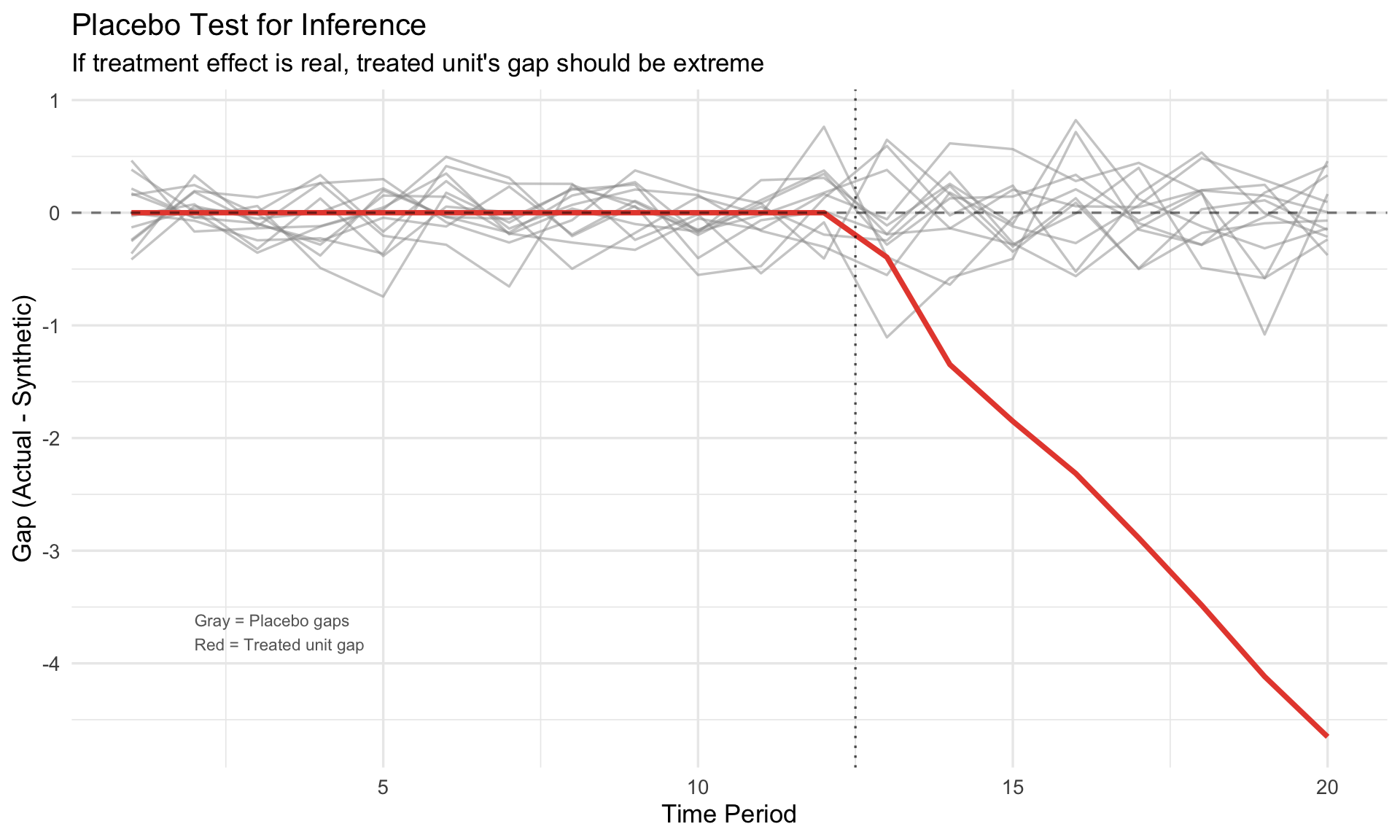
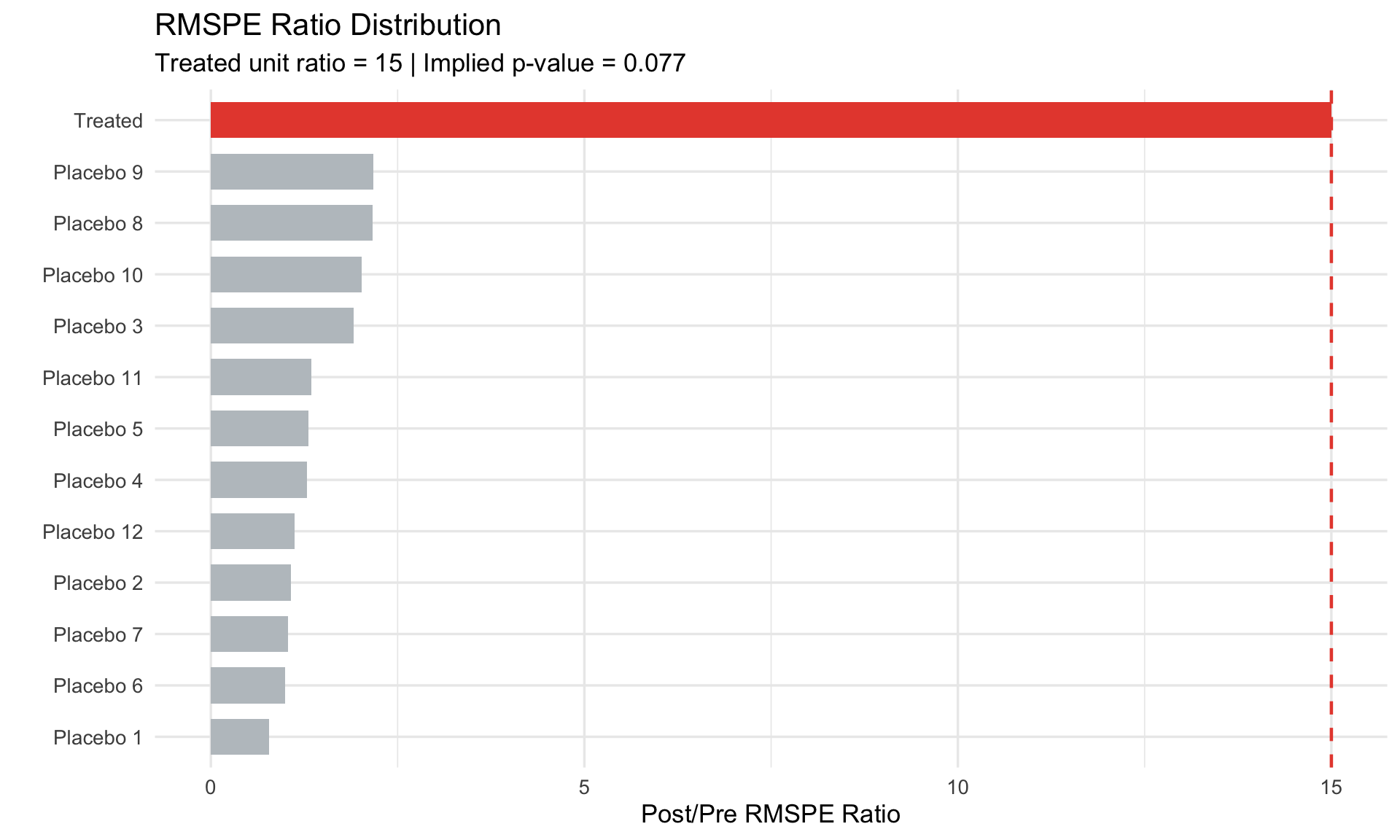
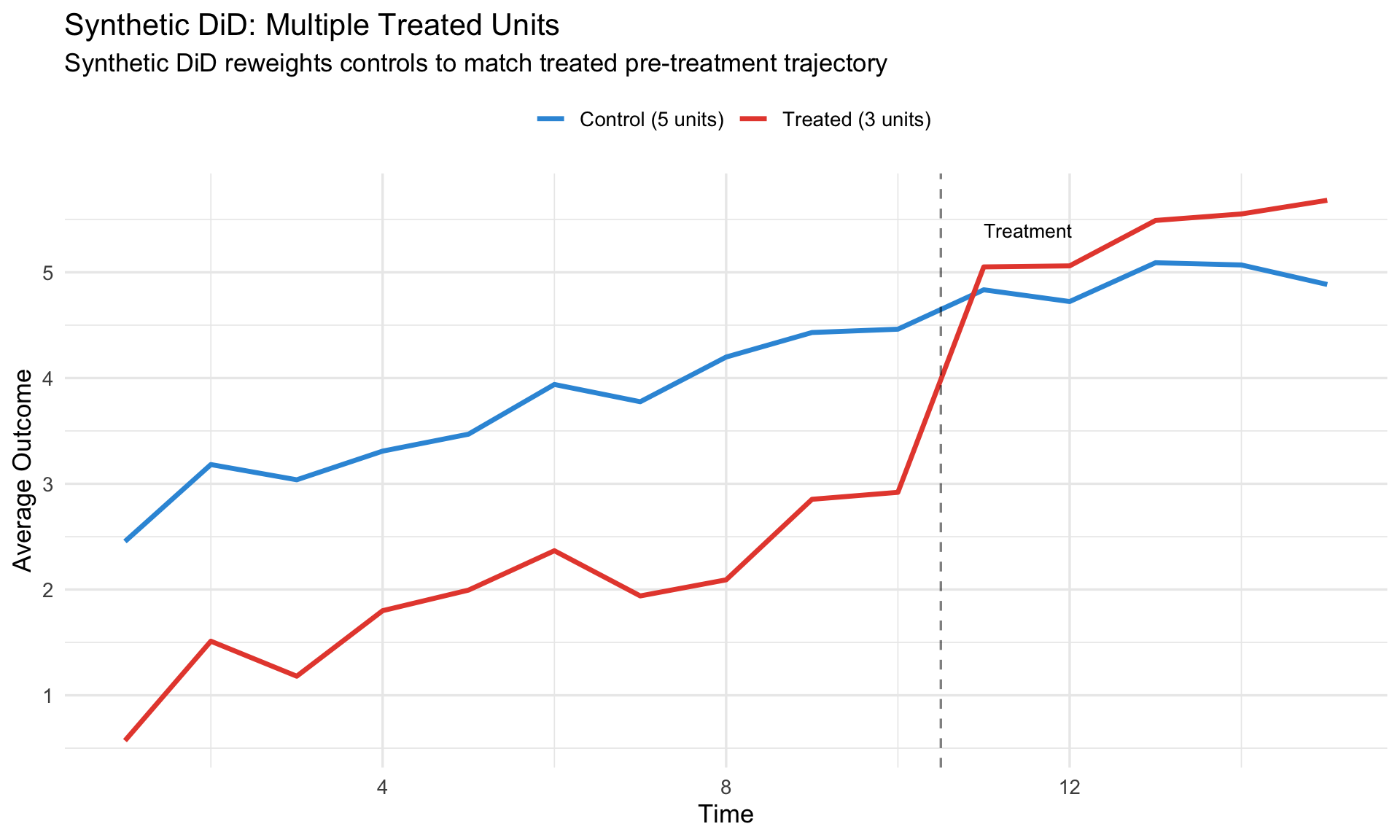
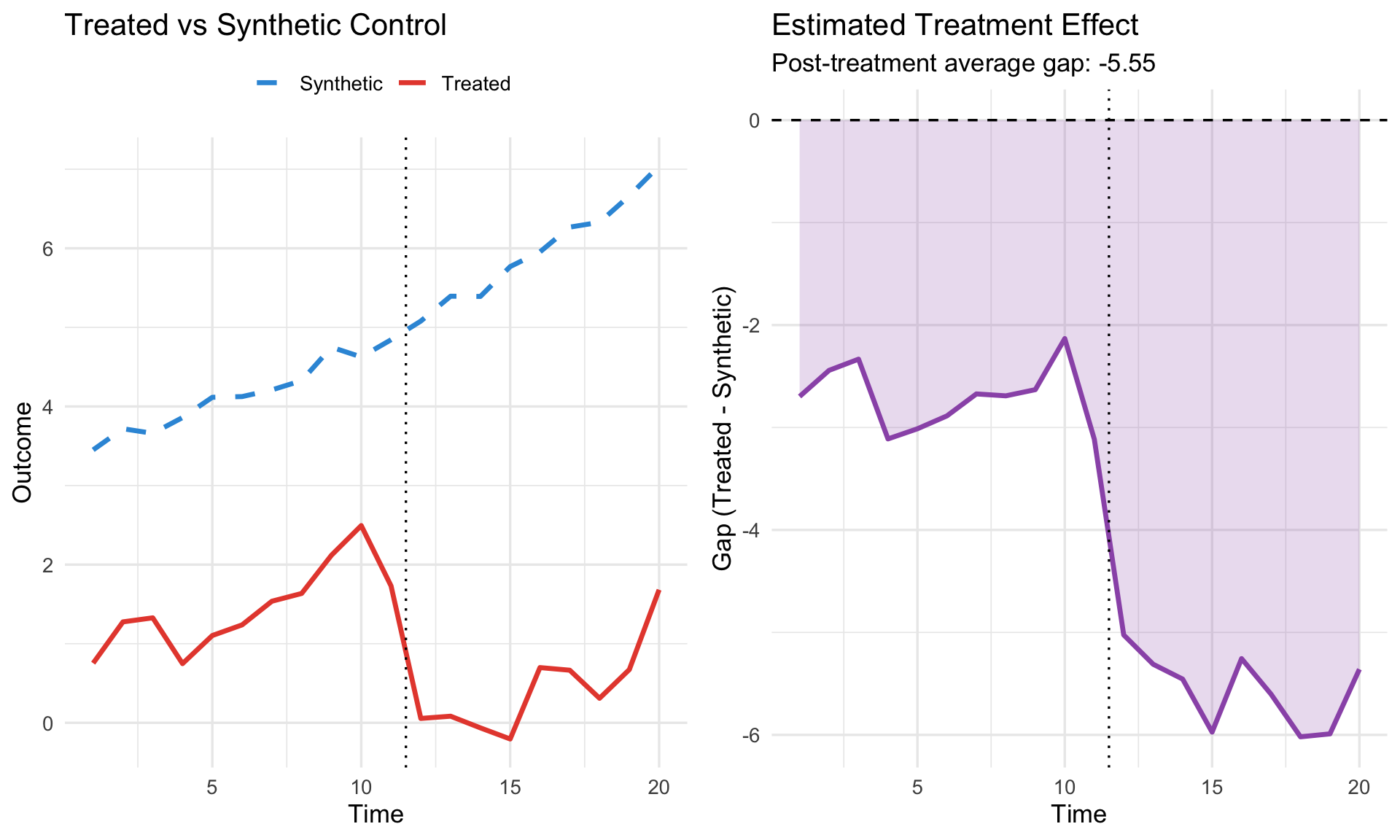
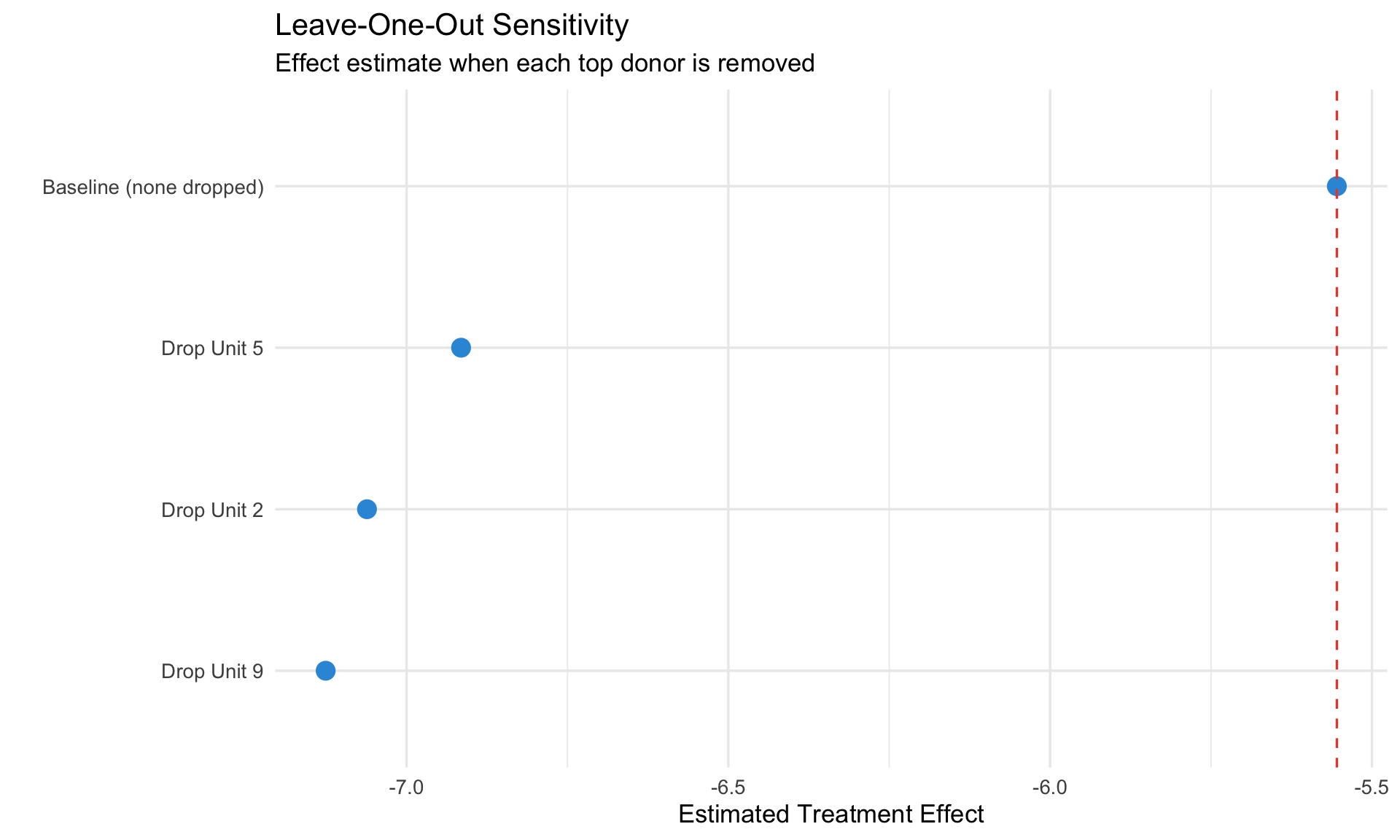
# Simulate SCM scenario
set.seed(123)
T_total <- 20
T0 <- 12 # Treatment after period 12
# Treated unit trajectory
treated_base <- cumsum(c(0, rnorm(T0-1, 0.3, 0.2)))
treated_post <- treated_base[T0] + cumsum(rnorm(T_total - T0, -0.1, 0.25))
treated <- c(treated_base, treated_post)
# Donor units (5 potential controls)
donors <- lapply(1:5, function(i) {
base <- cumsum(c(0, rnorm(T_total-1, 0.25 + 0.05*i, 0.3)))
data.frame(time = 1:T_total, unit = paste("Donor", i), y = base)
}) %>% bind_rows()
# Optimal weights (illustrative - found to match pre-treatment)
weights <- c(0.45, 0.30, 0.15, 0.10, 0.00)
# Construct synthetic control
synthetic <- donors %>%
mutate(weight = case_when(
unit == "Donor 1" ~ weights[1],
unit == "Donor 2" ~ weights[2],
unit == "Donor 3" ~ weights[3],
unit == "Donor 4" ~ weights[4],
TRUE ~ weights[5]
)) %>%
group_by(time) %>%
summarize(y = sum(y * weight), .groups = "drop")
# Combine for plotting
treated_df <- data.frame(time = 1:T_total, y = treated, unit = "Treated")
ggplot() +
# Donor units (faded)
geom_line(data = donors, aes(x = time, y = y, group = unit),
color = "gray70", alpha = 0.4, linewidth = 0.7) +
# Synthetic control
geom_line(data = synthetic, aes(x = time, y = y),
color = "#3498db", linewidth = 1.3, linetype = "dashed") +
# Treated unit
geom_line(data = treated_df, aes(x = time, y = y),
color = "#e74c3c", linewidth = 1.3) +
# Treatment line
geom_vline(xintercept = T0 + 0.5, linetype = "dotted", alpha = 0.7) +
annotate("text", x = T0 + 1, y = max(treated) * 0.95,
label = "Treatment", hjust = 0, size = 3.5) +
# Gap annotation
annotate("segment", x = T_total - 1, xend = T_total - 1,
y = treated[T_total-1], yend = synthetic$y[T_total-1],
arrow = arrow(ends = "both", length = unit(0.08, "inches")),
color = "#9b59b6", linewidth = 1) +
annotate("text", x = T_total - 0.5,
y = mean(c(treated[T_total-1], synthetic$y[T_total-1])),
label = expression(hat(tau)), hjust = 0, size = 4, color = "#9b59b6") +
labs(title = "Synthetic Control Method",
subtitle = "Red = Treated | Blue dashed = Synthetic Control | Gray = Donor Pool",
x = "Time Period", y = "Outcome") +
theme(legend.position = "none")