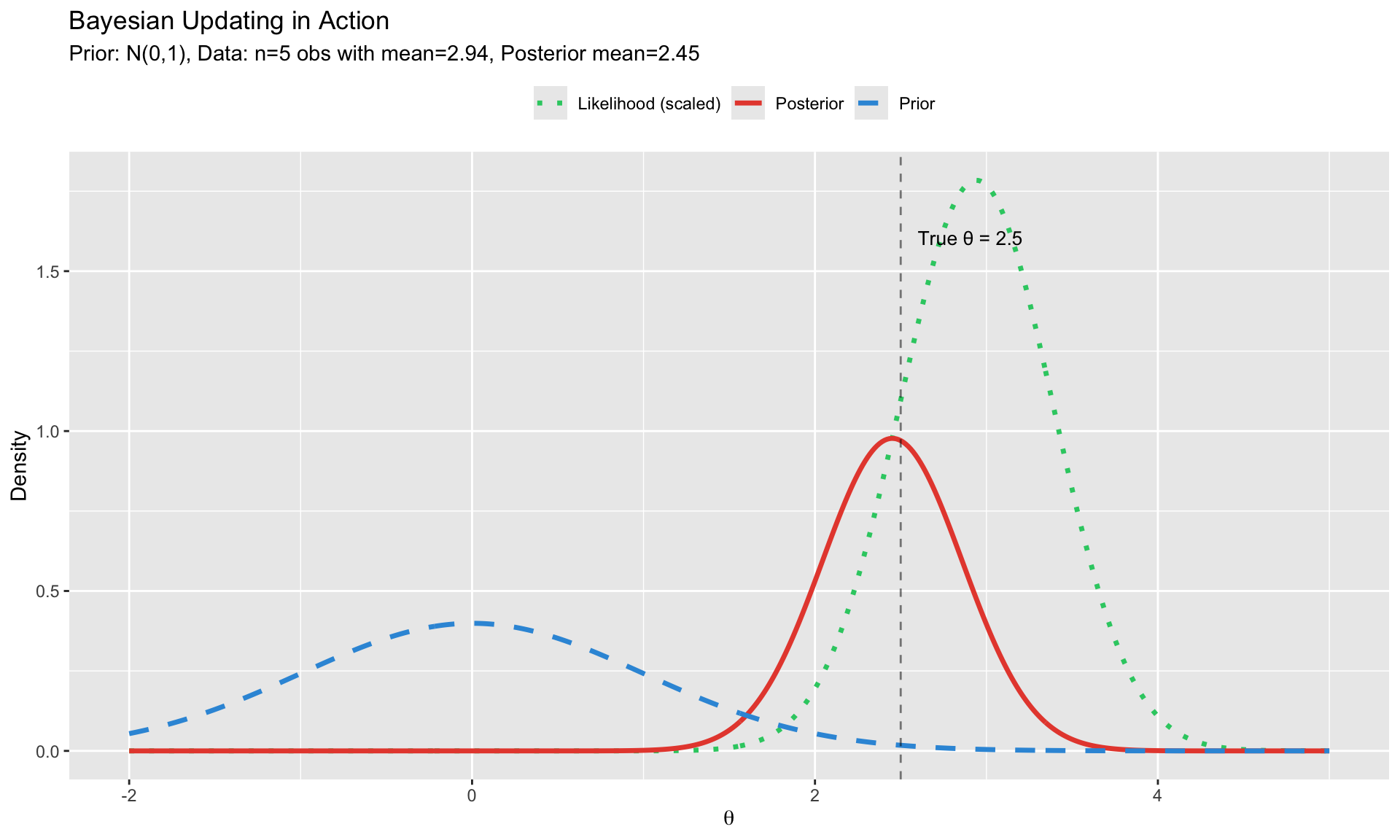
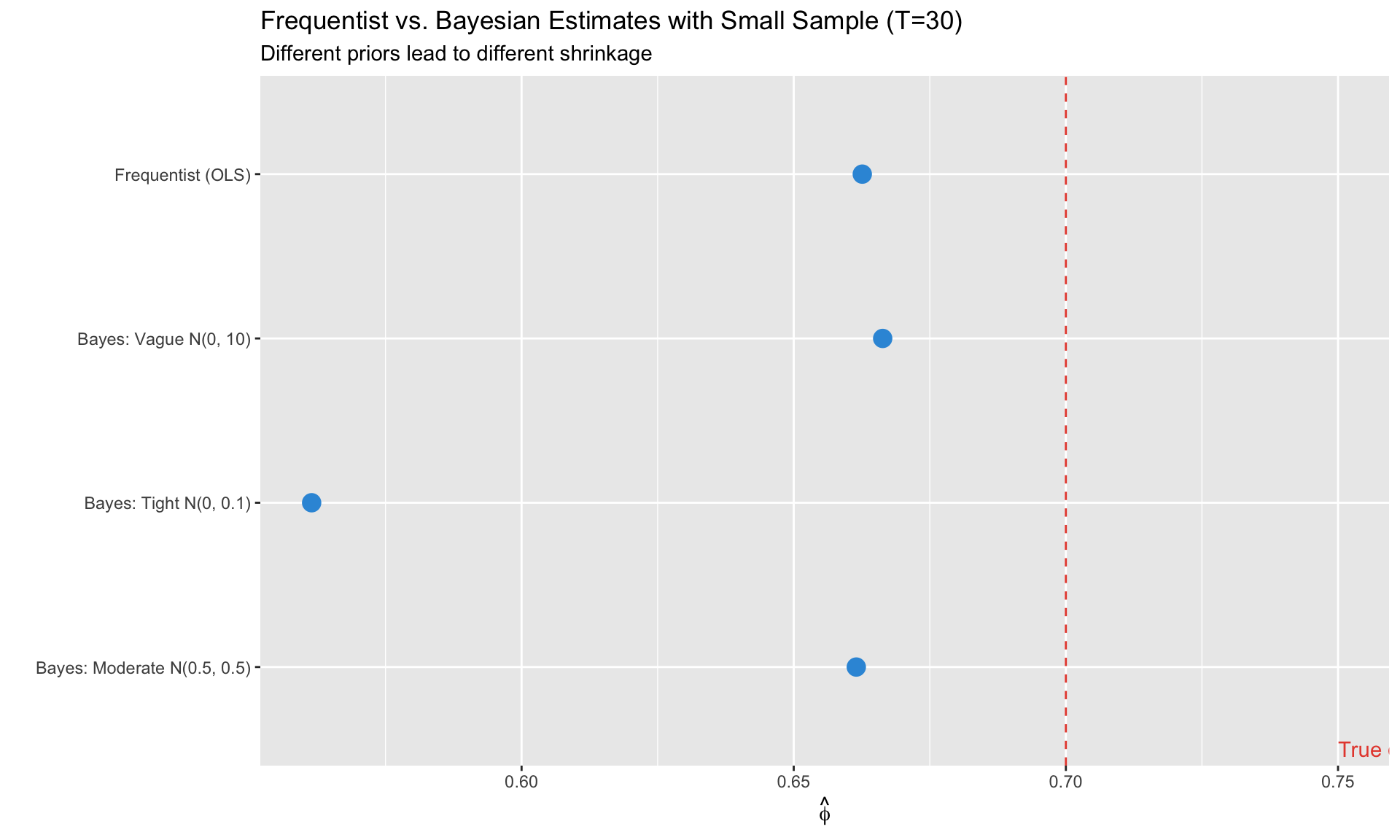
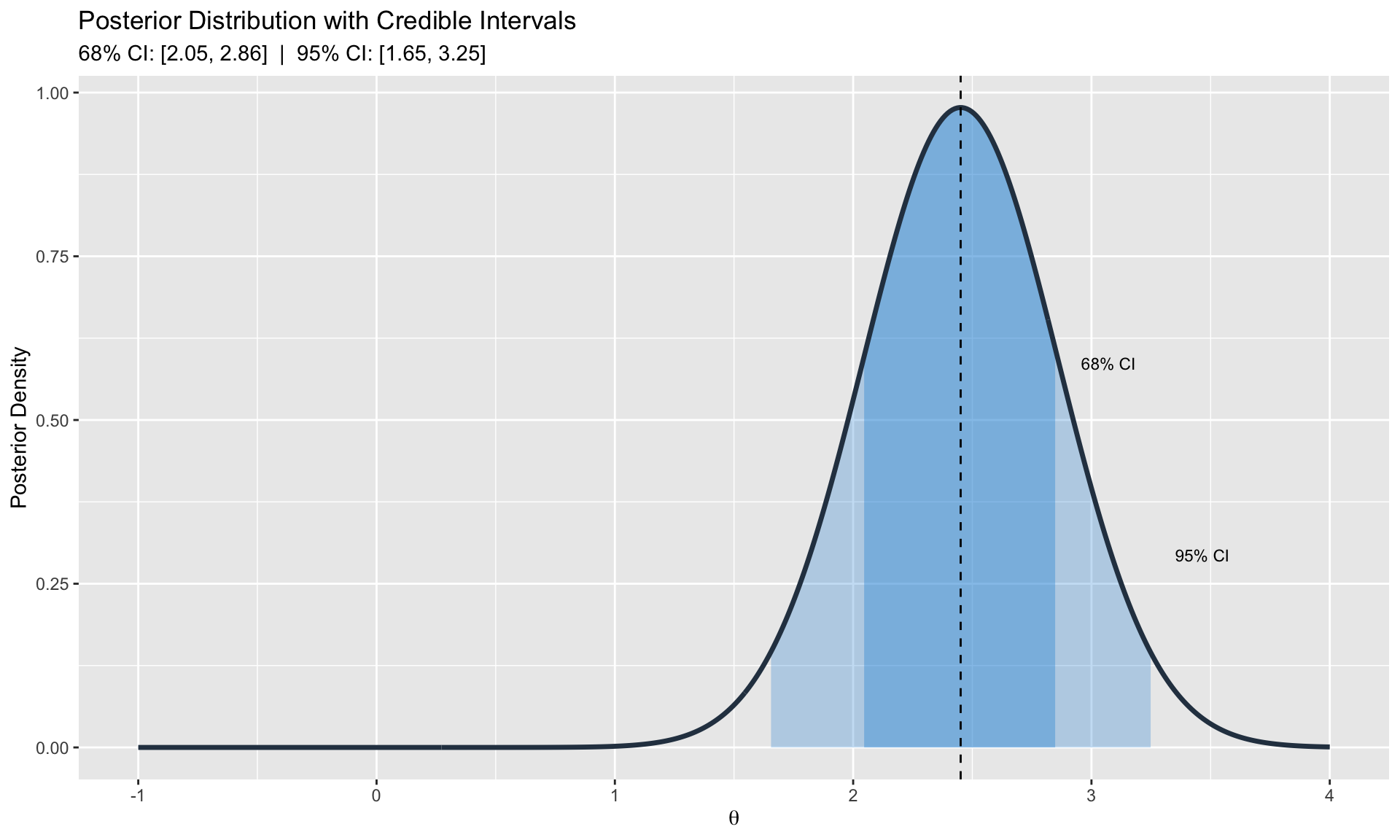
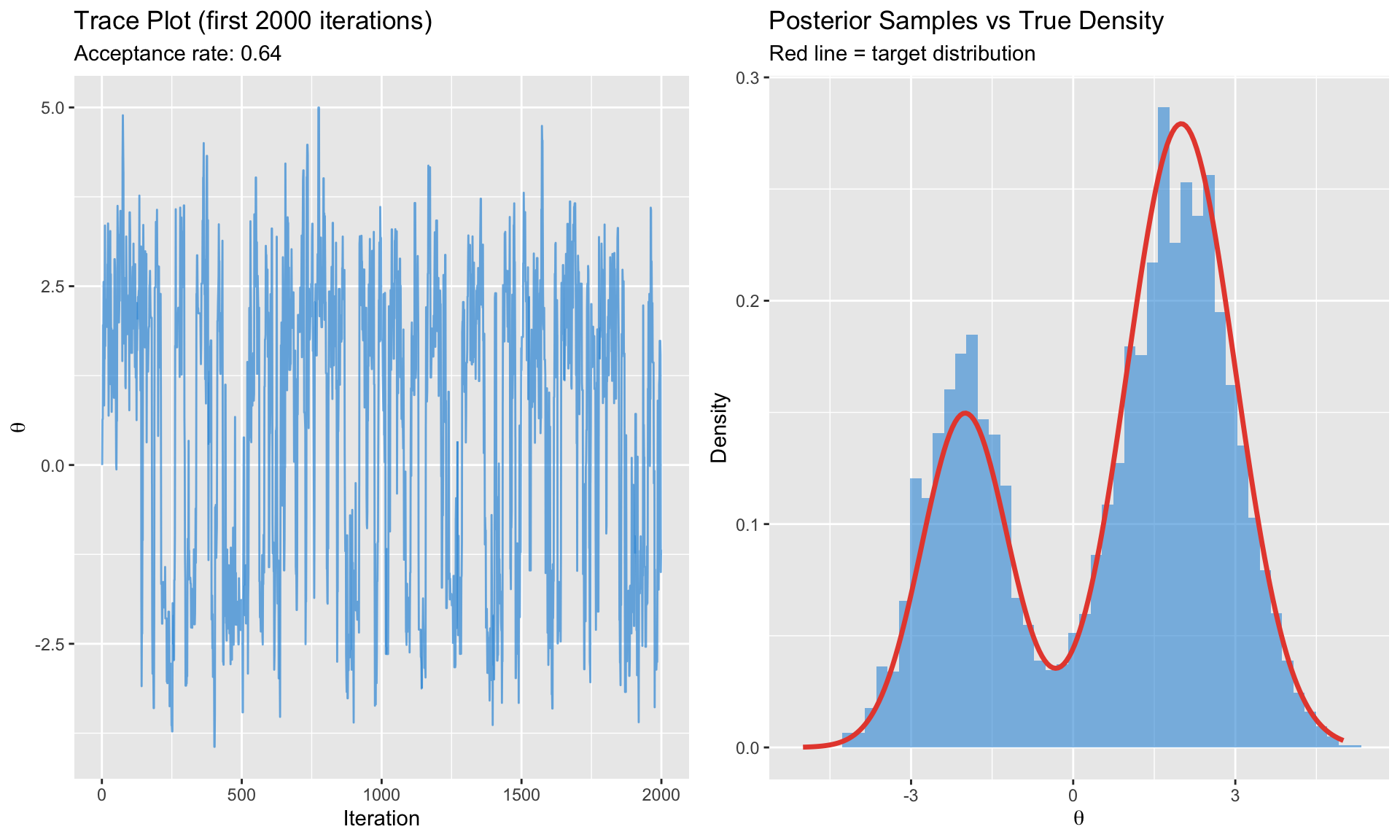
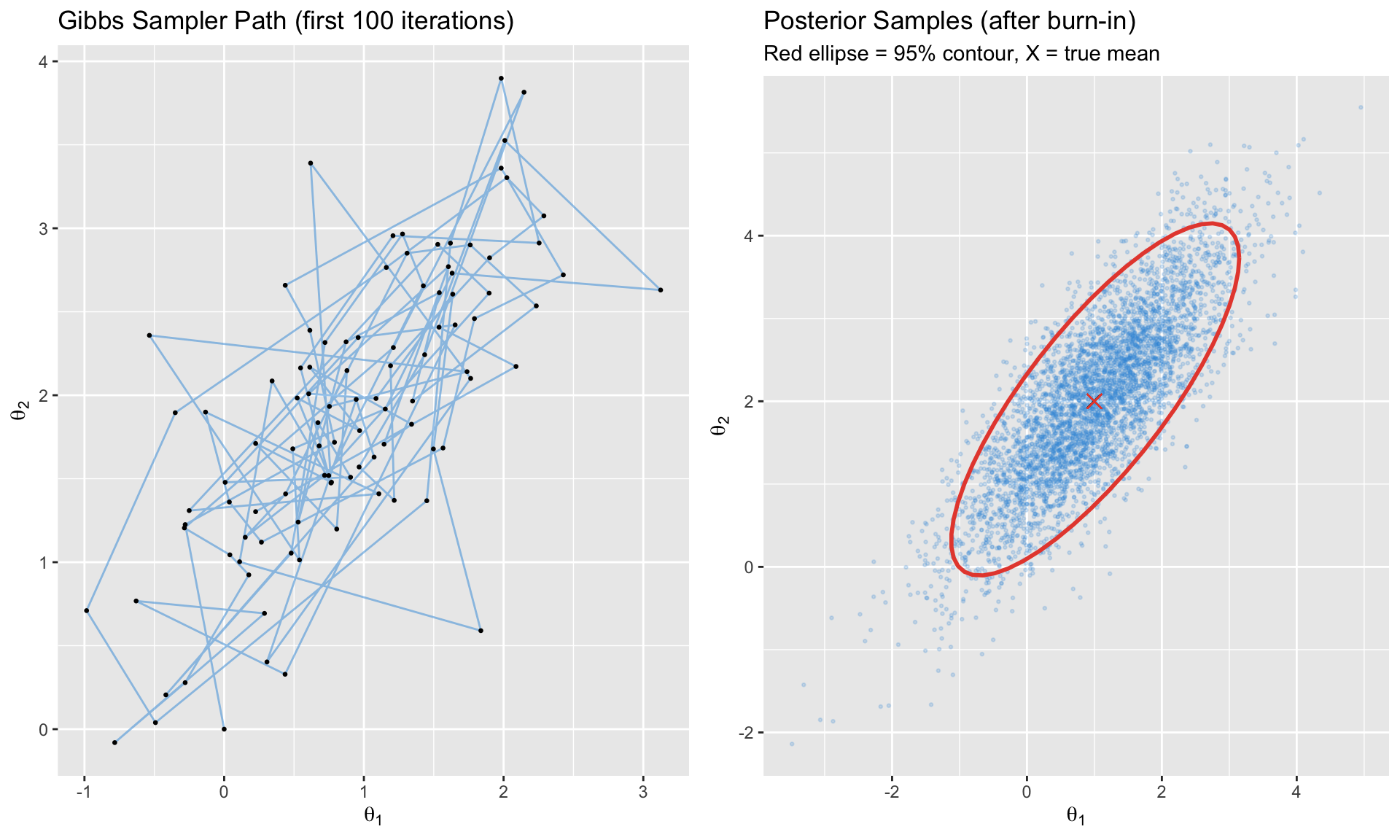
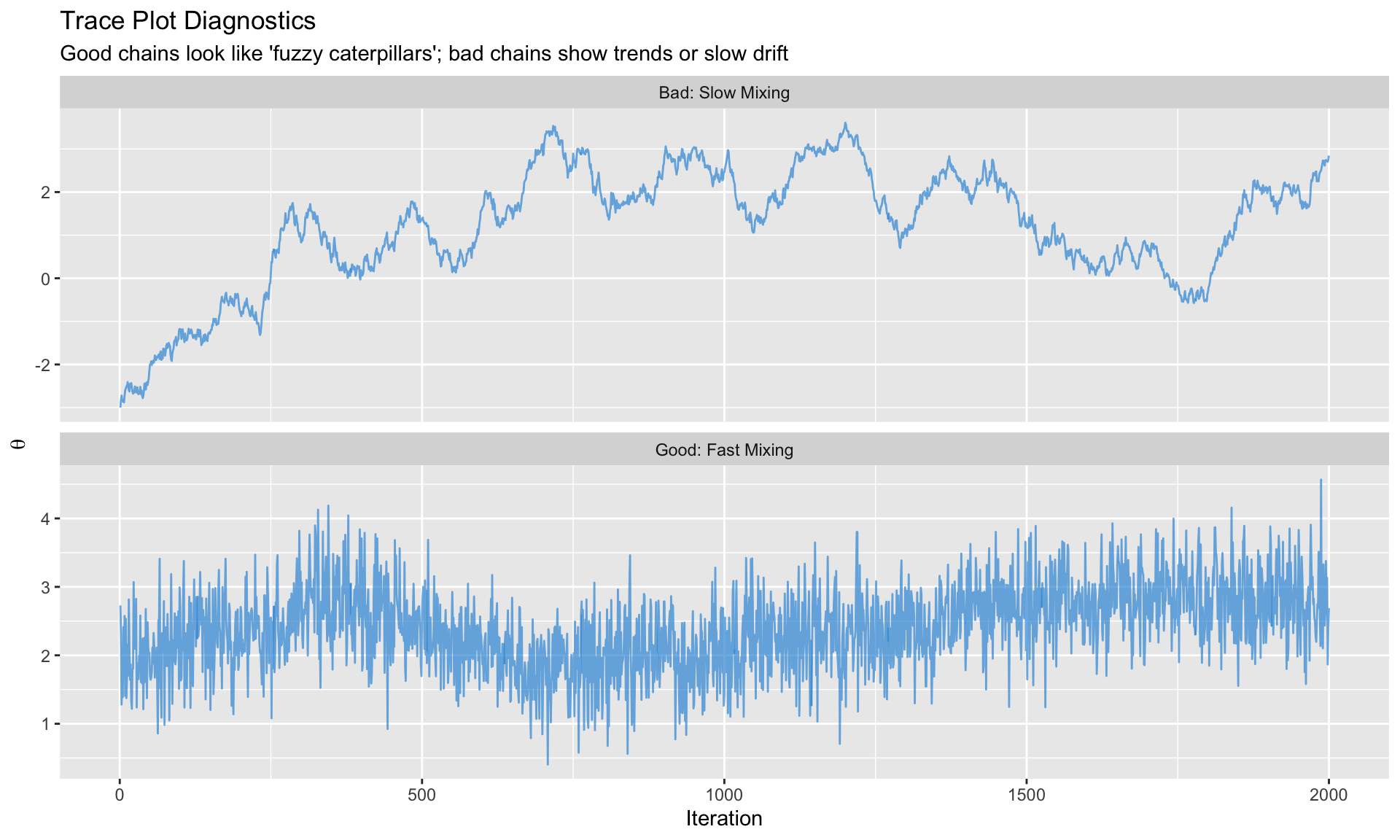
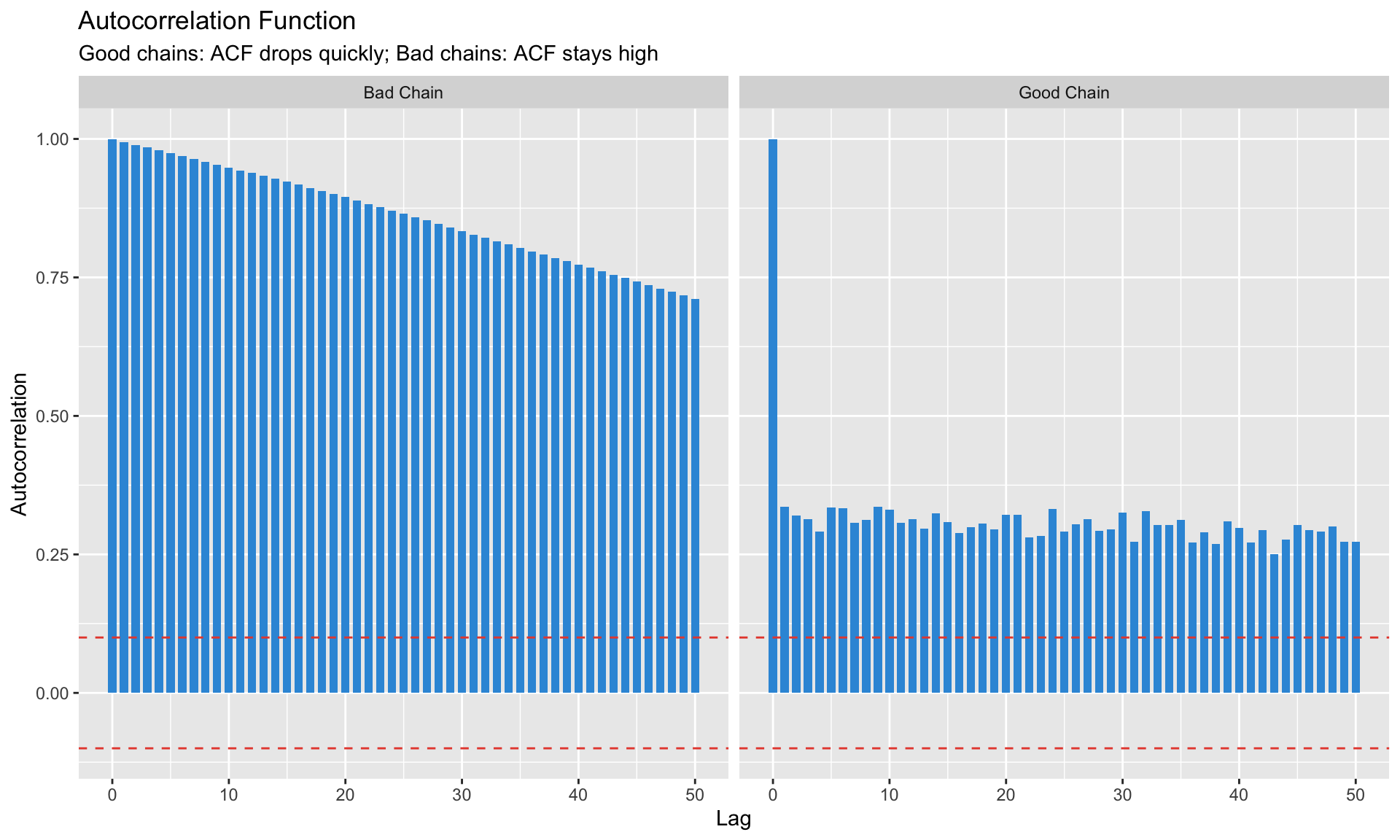
# Gibbs sampler for bivariate normal
gibbs_bivariate_normal <- function(n_iter, mu, Sigma) {
# Target: N(mu, Sigma)
rho <- Sigma[1,2] / sqrt(Sigma[1,1] * Sigma[2,2])
sd1 <- sqrt(Sigma[1,1])
sd2 <- sqrt(Sigma[2,2])
samples <- matrix(0, n_iter, 2)
samples[1, ] <- c(0, 0) # start
for (i in 2:n_iter) {
# Draw x1 | x2
cond_mean1 <- mu[1] + rho * sd1/sd2 * (samples[i-1, 2] - mu[2])
cond_sd1 <- sd1 * sqrt(1 - rho^2)
samples[i, 1] <- rnorm(1, cond_mean1, cond_sd1)
# Draw x2 | x1
cond_mean2 <- mu[2] + rho * sd2/sd1 * (samples[i, 1] - mu[1])
cond_sd2 <- sd2 * sqrt(1 - rho^2)
samples[i, 2] <- rnorm(1, cond_mean2, cond_sd2)
}
samples
}
# Run Gibbs
mu <- c(1, 2)
Sigma <- matrix(c(1, 0.8, 0.8, 1), 2, 2)
gibbs_samples <- gibbs_bivariate_normal(5000, mu, Sigma)
# Plot trajectory and samples
gibbs_df <- data.frame(
x1 = gibbs_samples[, 1],
x2 = gibbs_samples[, 2],
iteration = 1:nrow(gibbs_samples)
)
# First 100 iterations showing path
p1 <- ggplot(gibbs_df[1:100, ], aes(x = x1, y = x2)) +
geom_path(alpha = 0.5, color = "#3498db") +
geom_point(size = 0.5) +
labs(title = "Gibbs Sampler Path (first 100 iterations)",
x = expression(theta[1]), y = expression(theta[2]))
# All samples
p2 <- ggplot(gibbs_df[501:5000, ], aes(x = x1, y = x2)) +
geom_point(alpha = 0.2, size = 0.5, color = "#3498db") +
stat_ellipse(level = 0.95, color = "#e74c3c", size = 1) +
geom_point(aes(x = mu[1], y = mu[2]), color = "#e74c3c", size = 3, shape = 4) +
labs(title = "Posterior Samples (after burn-in)",
subtitle = "Red ellipse = 95% contour, X = true mean",
x = expression(theta[1]), y = expression(theta[2]))
gridExtra::grid.arrange(p1, p2, ncol = 2)