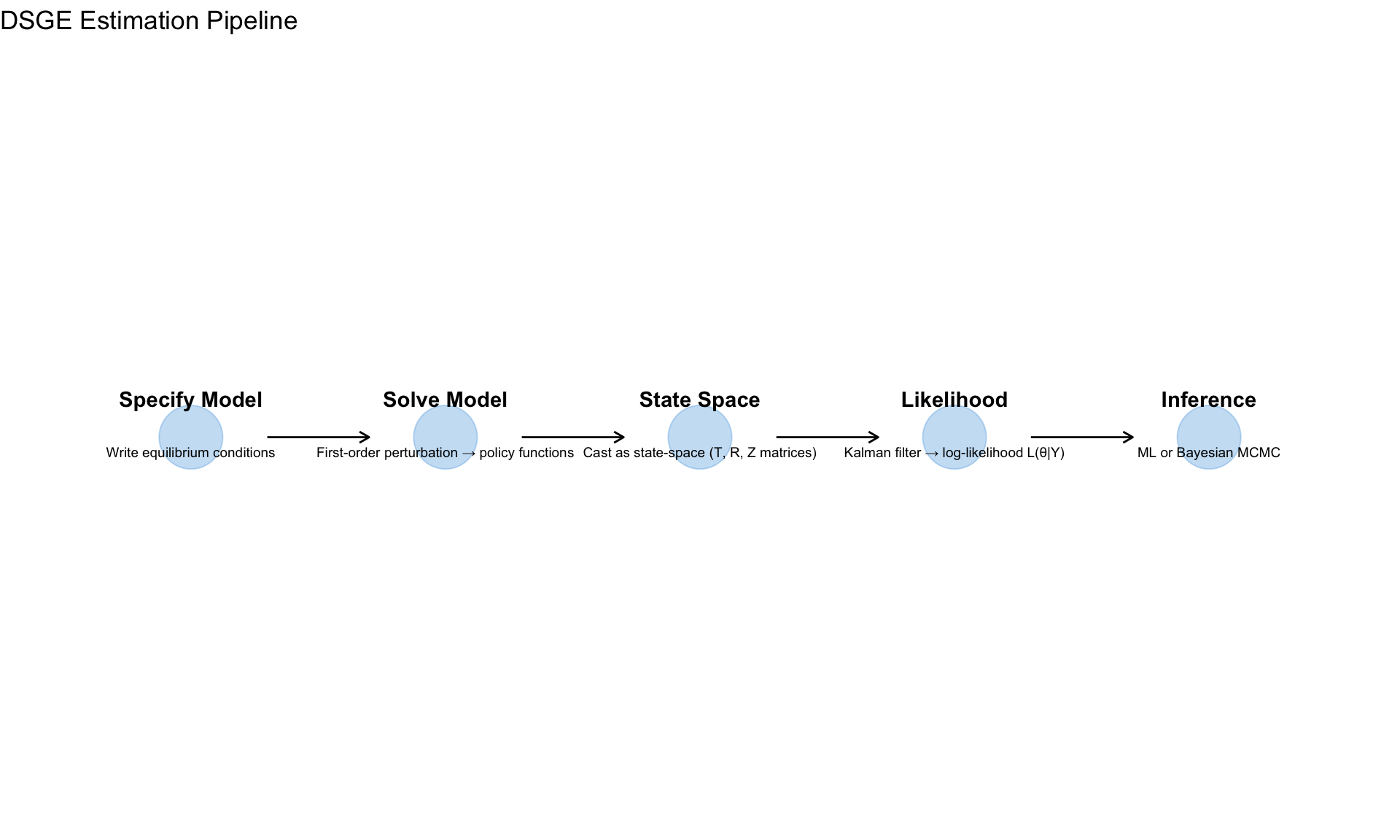
DSGE Estimation
The Kalman Filter, Bayesian Methods, and Model Comparison
From Model to Data
Module 10 showed how to solve DSGE models. Now we estimate them—finding parameter values that make the model consistent with observed data.
NoteThe Estimation Challenge
DSGE models have latent states (unobserved variables like potential output, natural rate) that we must infer while simultaneously estimating parameters.
The Workflow
State Space Representation
After solving the DSGE model (Module 10), we have:
\[ \hat{y}_t = G_x \hat{y}_{t-1} + G_u u_t \]
This is the transition equation. We add an observation equation linking model states to observables:
The State Space Form
\[ \underbrace{s_t = T s_{t-1} + R \eta_t}_{\text{Transition}} \quad \eta_t \sim N(0, Q) \]
\[ \underbrace{y_t = Z s_t + d + \varepsilon_t}_{\text{Observation}} \quad \varepsilon_t \sim N(0, H) \]
| Component | Meaning | From DSGE |
|---|---|---|
| \(s_t\) | State vector (all model variables) | Solution states |
| \(T\) | Transition matrix | \(G_x\) from perturbation |
| \(R\) | Shock impact | \(G_u\) from perturbation |
| \(Q\) | Shock variance-covariance | \(\text{diag}(\sigma_1^2, \ldots, \sigma_k^2)\) |
| \(y_t\) | Observables (data) | GDP growth, inflation, rate |
| \(Z\) | Selection/mapping matrix | Which states are observed |
| \(H\) | Measurement error variance | Often zero or small |
Example: 3-Variable NK Model
Observables: \(y_t = (\Delta \log Y_t, \pi_t, i_t)'\)
States: \(s_t = (\hat{y}_t, \hat{\pi}_t, \hat{i}_t, \hat{a}_t, \hat{\varepsilon}^m_t)'\)
Mapping: \[ Z = \begin{pmatrix} 1 & 0 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 & 0 \\ 0 & 0 & 1 & 0 & 0 \end{pmatrix} \]
The first three states are directly observed (up to measurement error).
The Kalman Filter
The Kalman filter recursively computes the likelihood \(L(\theta | Y)\) where \(\theta\) are the DSGE parameters.
The Algorithm
For each time period \(t = 1, \ldots, T\):
Step 1: Prediction
Given information up to \(t-1\): \[ s_{t|t-1} = T s_{t-1|t-1} \] \[ P_{t|t-1} = T P_{t-1|t-1} T' + R Q R' \]
where \(P_{t|t-1}\) is the variance of the state forecast.
Step 2: Innovation
Compare prediction to actual observation: \[ v_t = y_t - Z s_{t|t-1} - d \] \[ F_t = Z P_{t|t-1} Z' + H \]
\(v_t\) is the forecast error and \(F_t\) is its variance.
Step 3: Update
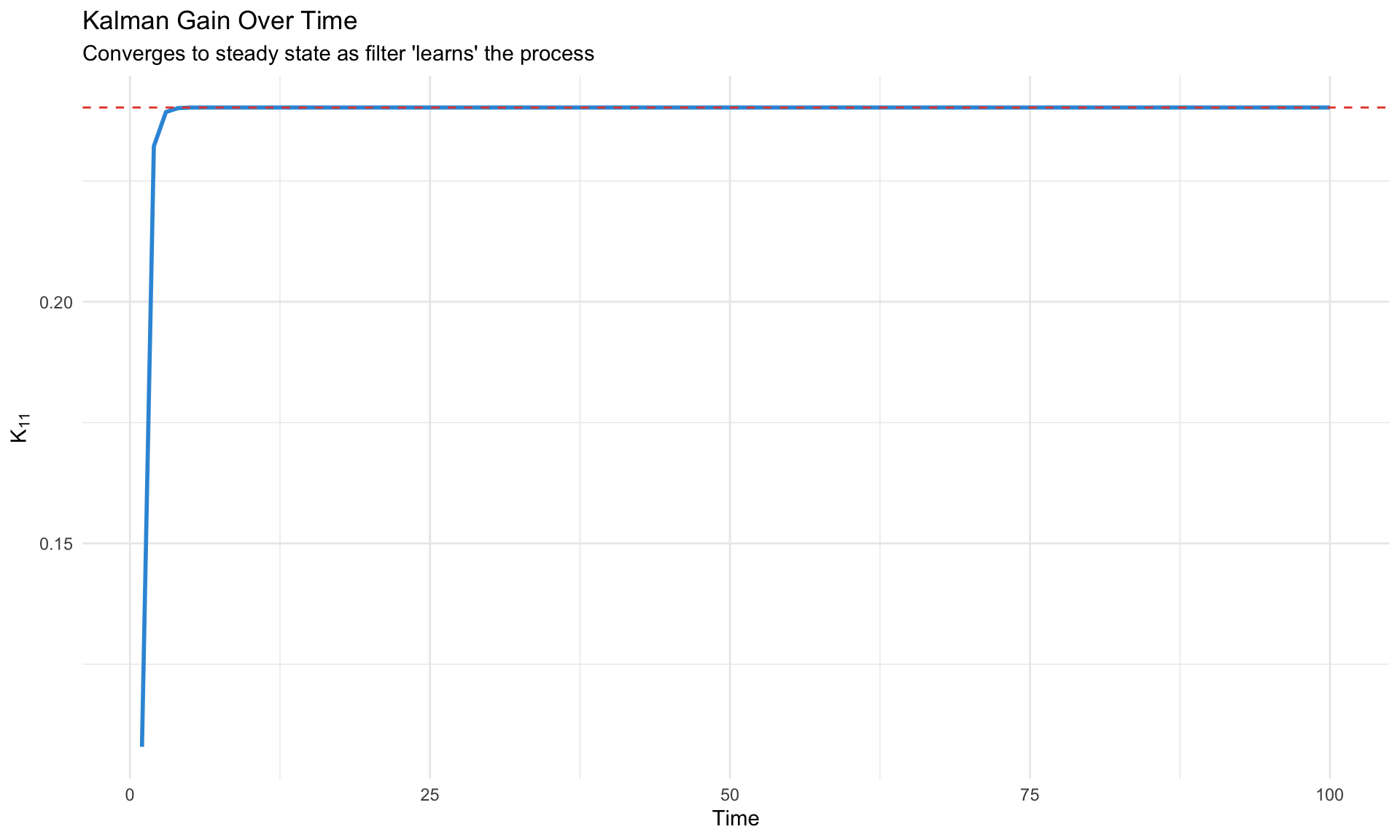
Incorporate new observation: \[ K_t = P_{t|t-1} Z' F_t^{-1} \] \[ s_{t|t} = s_{t|t-1} + K_t v_t \] \[ P_{t|t} = (I - K_t Z) P_{t|t-1} \]
\(K_t\) is the Kalman gain—how much to adjust the state given the forecast error.
Step 4: Likelihood Contribution
\[ \log L_t = -\frac{n_y}{2} \log(2\pi) - \frac{1}{2} \log|F_t| - \frac{1}{2} v_t' F_t^{-1} v_t \]
Total log-likelihood: \[ \log L(\theta | Y) = \sum_{t=1}^{T} \log L_t \]
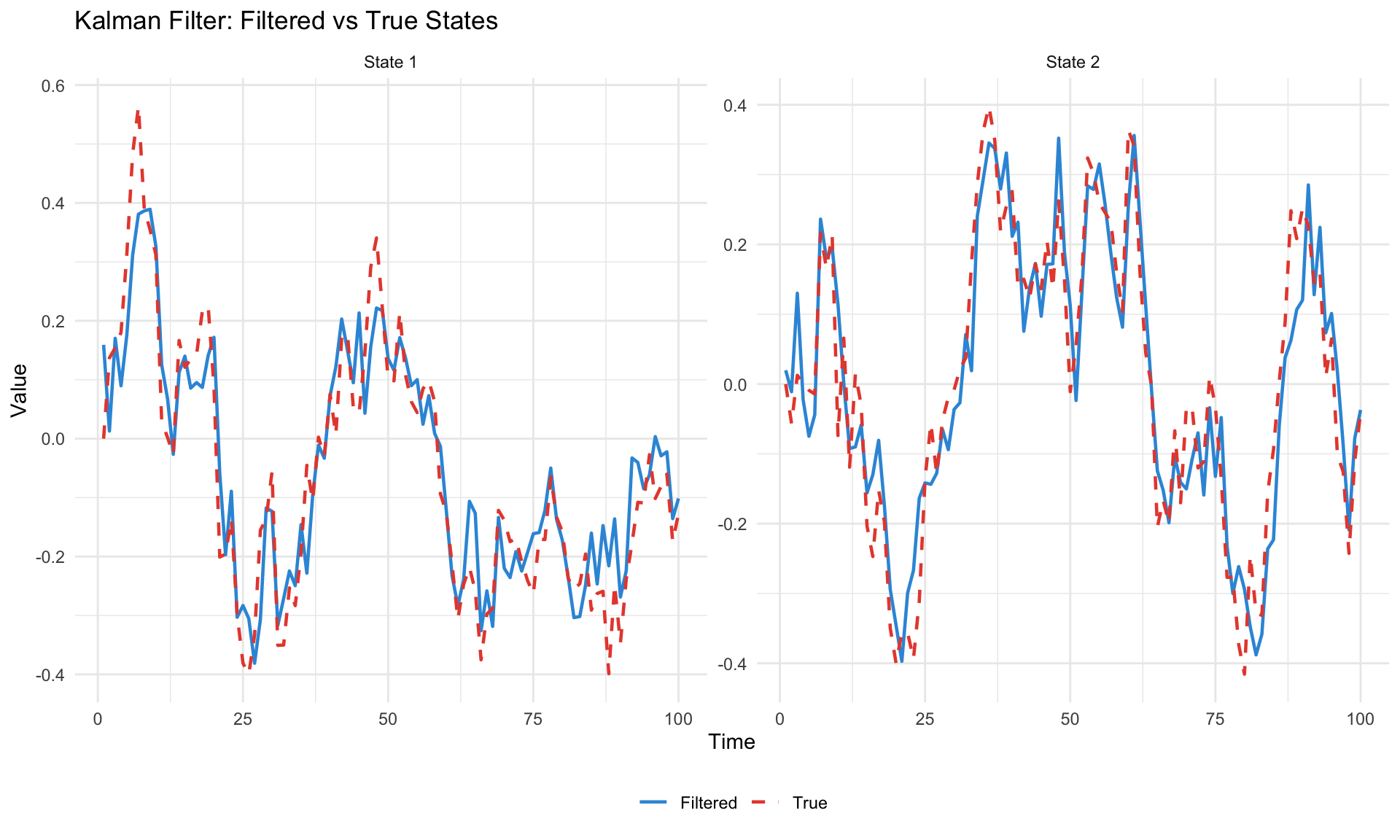
Kalman Gain Intuition
The Kalman gain \(K_t\) balances:
- Model confidence (small \(P_{t|t-1}\)) → trust the prediction, small \(K_t\)
- Observation precision (small \(H\)) → trust the data, large \(K_t\)
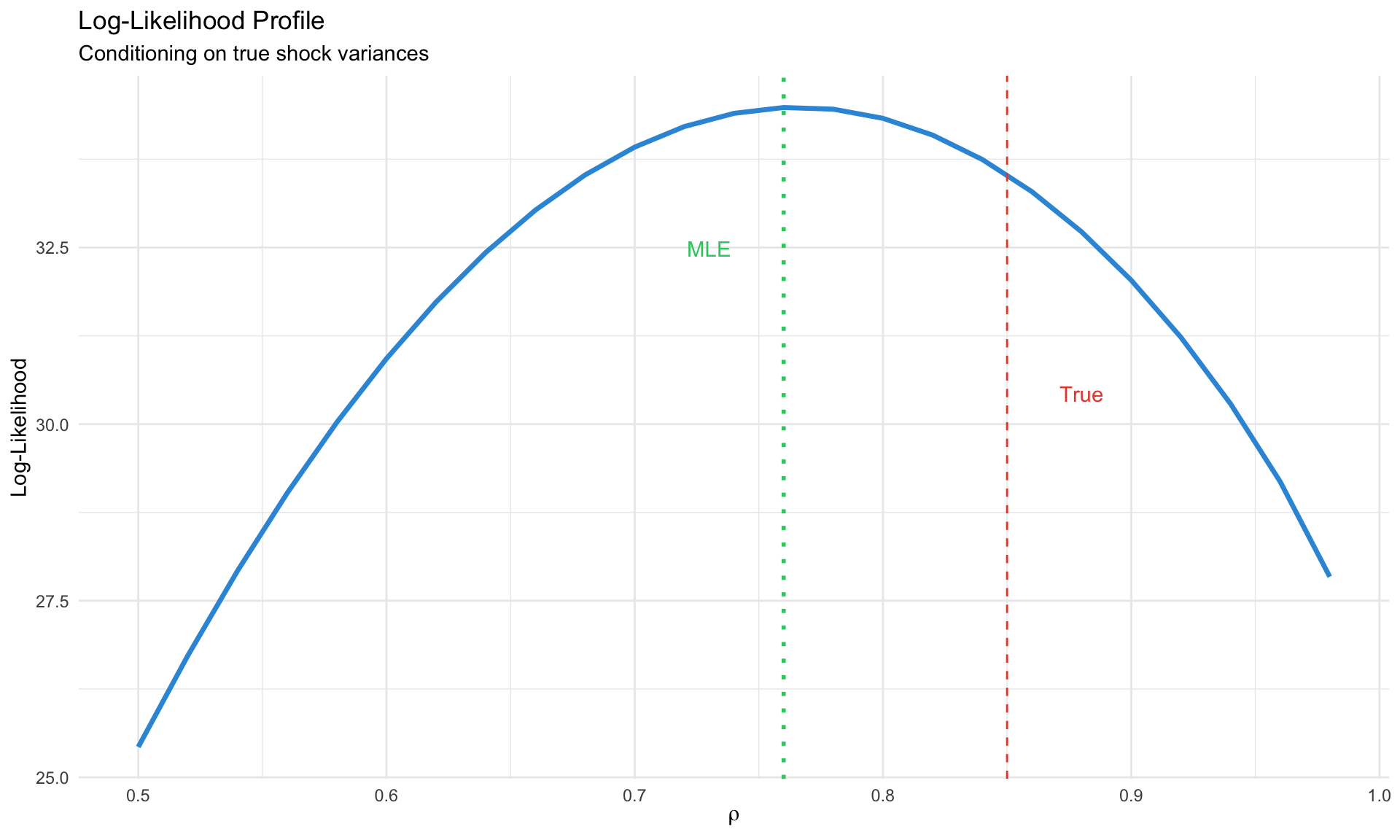
Maximum Likelihood Estimation
Given the Kalman filter likelihood, we can maximize:
\[ \hat{\theta}_{ML} = \arg\max_\theta \log L(\theta | Y) \]
The Challenge
For each candidate \(\theta\):
- Solve the DSGE → get \(T(\theta), R(\theta)\)
- Run Kalman filter → get \(\log L(\theta | Y)\)
This is computationally expensive. Gradient-free optimizers (Nelder-Mead, simulated annealing) or specialized methods (csminwel) are common.
Standard Errors
At the MLE, compute the Hessian (matrix of second derivatives):
\[ \hat{V}(\hat{\theta}) = -H^{-1}, \quad H_{ij} = \frac{\partial^2 \log L}{\partial \theta_i \partial \theta_j}\bigg|_{\hat{\theta}} \]
Standard errors: \(\text{SE}(\hat{\theta}_j) = \sqrt{\hat{V}_{jj}}\)
Bayesian Estimation
The Bayesian approach combines prior beliefs with data:
\[ \underbrace{p(\theta | Y)}_{\text{posterior}} \propto \underbrace{L(Y | \theta)}_{\text{likelihood}} \times \underbrace{p(\theta)}_{\text{prior}} \]
Why Bayesian for DSGE?
| Advantage | Explanation |
|---|---|
| Regularization | Priors prevent extreme/implausible estimates |
| Identification | Informative priors help weakly identified parameters |
| Full uncertainty | Posterior distribution, not just point estimate |
| Model comparison | Marginal likelihood is natural Bayesian output |
| Small samples | Works well with limited macro data |
Prior Selection
Priors should reflect economic knowledge without being too restrictive.
Standard Prior Distributions
| Parameter Type | Distribution | Rationale |
|---|---|---|
| Persistence (\(\rho\)) | Beta(a, b) | Bounded [0, 1] |
| Elasticities | Gamma(a, b) | Positive, right-skewed |
| Fractions (\(\alpha, \theta\)) | Beta(a, b) | Bounded [0, 1] |
| Shock std (\(\sigma\)) | Inv-Gamma(s, \(\nu\)) | Positive, proper |
| Policy weights (\(\phi_\pi\)) | Gamma or Normal | Positive or unrestricted |
| Discount factor (\(\beta\)) | Beta near 0.99 | Close to 1 |
Example: NK Model Priors
| Parameter | Distribution | Mean | SD | Interpretation |
|---|---|---|---|---|
| \(\beta\) | Beta | 0.9900 | 0.002 | Discount factor |
| \(\sigma\) | Gamma | 1.5000 | 0.250 | Risk aversion |
| \(\phi\) | Gamma | 2.0000 | 0.500 | Frisch elasticity |
| \(\theta\) | Beta | 0.7500 | 0.100 | Calvo parameter |
| \(\phi_\pi\) | Gamma | 1.5000 | 0.250 | Taylor: inflation |
| \(\phi_y\) | Gamma | 0.1250 | 0.050 | Taylor: output |
| \(\rho_i\) | Beta | 0.8000 | 0.100 | Rate smoothing |
| \(\rho_a\) | Beta | 0.9000 | 0.050 | Tech persistence |
| \(\sigma_a\) | Inv-Gamma | 0.0100 | 2.000 | Tech shock std |
| \(\sigma_m\) | Inv-Gamma | 0.0025 | 2.000 | MP shock std |
Metropolis-Hastings MCMC
The posterior \(p(\theta | Y)\) is rarely available analytically. We use Markov Chain Monte Carlo (MCMC) to sample from it.
The Algorithm
Initialize: Start at some \(\theta^{(0)}\) (often the posterior mode)
Propose: Draw candidate \(\theta^* \sim q(\theta^* | \theta^{(g)})\)
- Common: Random walk \(\theta^* = \theta^{(g)} + \varepsilon\), \(\varepsilon \sim N(0, c \cdot \Sigma)\)
- \(\Sigma\) = inverse Hessian at mode; \(c\) = scaling factor
Accept/Reject: \[ \alpha = \min\left(1, \frac{p(\theta^* | Y)}{p(\theta^{(g)} | Y)}\right) = \min\left(1, \frac{L(Y|\theta^*) p(\theta^*)}{L(Y|\theta^{(g)}) p(\theta^{(g)})}\right) \]
- Draw \(u \sim \text{Uniform}(0, 1)\)
- If \(u < \alpha\): accept \(\theta^{(g+1)} = \theta^*\)
- Else: reject \(\theta^{(g+1)} = \theta^{(g)}\)
Repeat for \(G\) draws; discard first \(B\) as burn-in
Acceptance rate: 0.793 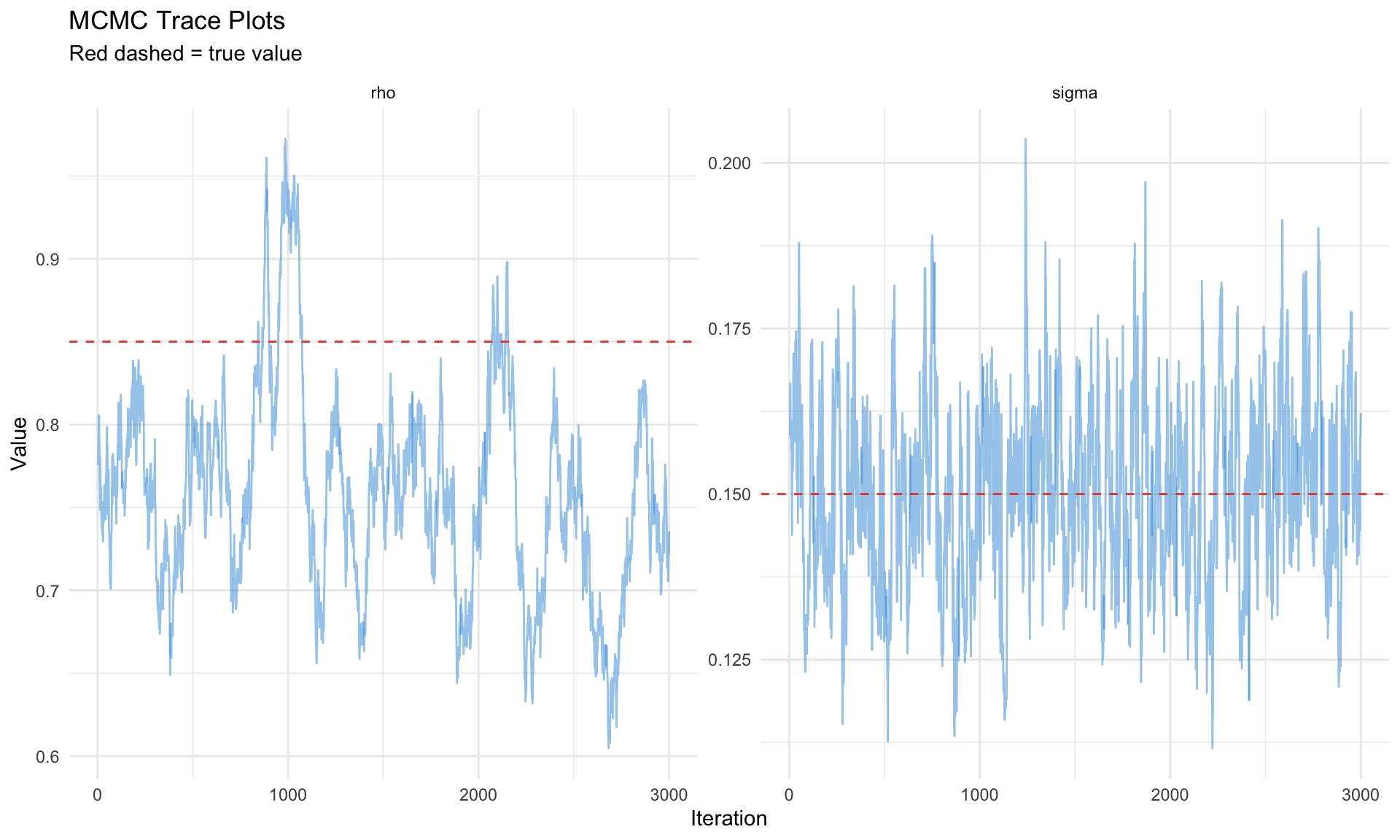
Tuning the Proposal
Target acceptance rate: 20-30% for random walk MH
| Acceptance Rate | Diagnosis | Action |
|---|---|---|
| < 10% | Proposals too bold | Decrease \(c\) |
| 20-30% | Optimal | Keep |
| > 50% | Proposals too timid | Increase \(c\) |
Dynare’s mh_jscale parameter controls this.
Dynare Estimation
Dynare automates DSGE estimation with the estimation command.
Complete Example: 3-Equation NK Model
%% nk_estimation.mod
%% Preamble
var y pi i a eps_m;
varexo eta_a eta_m;
parameters BETA SIGMA KAPPA PHI_PI PHI_Y RHO_I RHO_A;
%% Calibrated parameters
BETA = 0.99;
SIGMA = 1;
%% Model
model(linear);
% IS curve
y = y(+1) - (1/SIGMA) * (i - pi(+1));
% Phillips curve
pi = BETA * pi(+1) + KAPPA * y;
% Taylor rule
i = RHO_I * i(-1) + (1 - RHO_I) * (PHI_PI * pi + PHI_Y * y) + eps_m;
% Shocks
a = RHO_A * a(-1) + eta_a; % technology (affects natural rate)
eps_m = eta_m; % monetary policy
end;
%% Steady state
initval;
y = 0; pi = 0; i = 0; a = 0; eps_m = 0;
end;
steady;
check;
%% Shocks
shocks;
var eta_a; stderr 0.01;
var eta_m; stderr 0.0025;
end;
%% Observables (must match data columns)
varobs y pi i;
%% Estimated parameters with priors
estimated_params;
% Structural
KAPPA, gamma_pdf, 0.1, 0.05;
% Policy rule
PHI_PI, gamma_pdf, 1.5, 0.25;
PHI_Y, gamma_pdf, 0.125, 0.05;
RHO_I, beta_pdf, 0.8, 0.1;
% Shock processes
RHO_A, beta_pdf, 0.9, 0.05;
stderr eta_a, inv_gamma_pdf, 0.01, 2;
stderr eta_m, inv_gamma_pdf, 0.0025, 2;
end;
%% Estimation
estimation(
datafile = 'us_macro_data.csv',
first_obs = 1,
mode_compute = 4, % csminwel optimizer
mode_check, % plot likelihood around mode
mh_replic = 100000, % MH draws
mh_nblocks = 2, % parallel chains
mh_jscale = 0.3, % proposal scaling
mh_drop = 0.5, % burn-in fraction
bayesian_irf, % posterior IRFs
smoother % smoothed states
);Key Estimation Options
| Option | Purpose | Typical Value |
|---|---|---|
mode_compute |
Optimizer for mode | 4 (csminwel) or 9 (dynare default) |
mode_check |
Plot likelihood around mode | Include |
mh_replic |
MH draws | 100,000-500,000 |
mh_nblocks |
Parallel chains | 2-4 |
mh_jscale |
Proposal scaling | 0.2-0.5 (tune for 25% acceptance) |
mh_drop |
Burn-in fraction | 0.5 |
bayesian_irf |
Compute posterior IRFs | Include |
smoother |
Compute smoothed states | Include |
Dynare Output
After estimation, Dynare produces:
| Output | Location | Content |
|---|---|---|
| Posterior mode | oo_.posterior_mode |
Point estimates |
| Posterior draws | oo_.posterior_draws |
MCMC chain |
| Prior/posterior plots | *_PriorPosterior.pdf |
Comparison |
| MCMC diagnostics | *_MCMCdiagnostics.pdf |
Convergence |
| IRFs | oo_.irfs |
Impulse responses |
| Smoothed variables | oo_.SmoothedVariables |
Filtered states |
| Marginal likelihood | oo_.MarginalDensity |
Model comparison |
Model Comparison
Marginal Likelihood
The marginal likelihood (or marginal data density) is:
\[ p(Y | M) = \int p(Y | \theta, M) p(\theta | M) d\theta \]
This integrates over parameter uncertainty, automatically penalizing complexity.
Bayes Factors
Compare models \(M_1\) vs \(M_2\):
\[ BF_{12} = \frac{p(Y | M_1)}{p(Y | M_2)} \]
| \(\log BF_{12}\) | Evidence for \(M_1\) |
|---|---|
| < 0 | Favors \(M_2\) |
| 0-1 | Weak |
| 1-3 | Positive |
| 3-5 | Strong |
| > 5 | Decisive |
Computing Marginal Likelihood
Laplace approximation (fast, less accurate): \[ \log p(Y | M) \approx \log p(Y | \hat{\theta}) + \log p(\hat{\theta}) + \frac{k}{2} \log(2\pi) - \frac{1}{2} \log|H| \]
Modified harmonic mean (Dynare default with MCMC): \[ \hat{p}(Y | M) = \left[\frac{1}{G} \sum_{g=1}^G \frac{f(\theta^{(g)})}{\tilde{p}(\theta^{(g)} | Y)}\right]^{-1} \]
where \(f\) is a truncated Normal centered at the posterior mode.
Log Bayes Factor (correct vs misspecified): 1.58 Interpretation: Positive evidence Diagnostics
MCMC Convergence
Trace Plots
Chains should: - Explore the full parameter space - Not get stuck in one region - Look like “hairy caterpillars” (good mixing)
Gelman-Rubin Statistic
For multiple chains, compare within-chain vs between-chain variance:
\[ \hat{R} = \sqrt{\frac{\hat{V}(\theta)}{W}} \]
Rule of thumb: \(\hat{R} < 1.1\) (ideally \(< 1.05\))
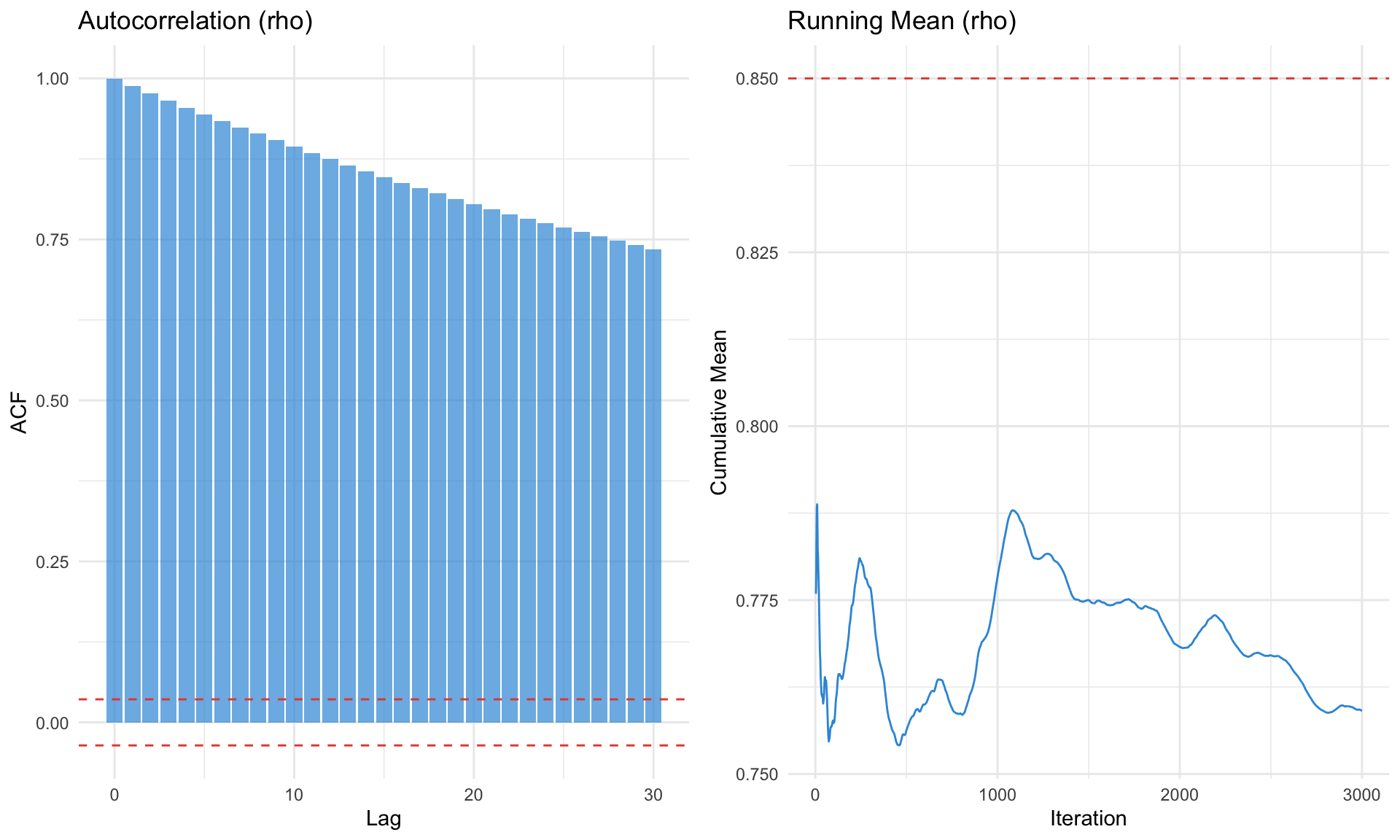
Effective Sample Size
Accounts for autocorrelation in the chain:
\[ \text{ESS} = \frac{n}{1 + 2\sum_{k=1}^\infty \rho_k} \]
Rule of thumb: ESS > 400 for reliable posterior summaries
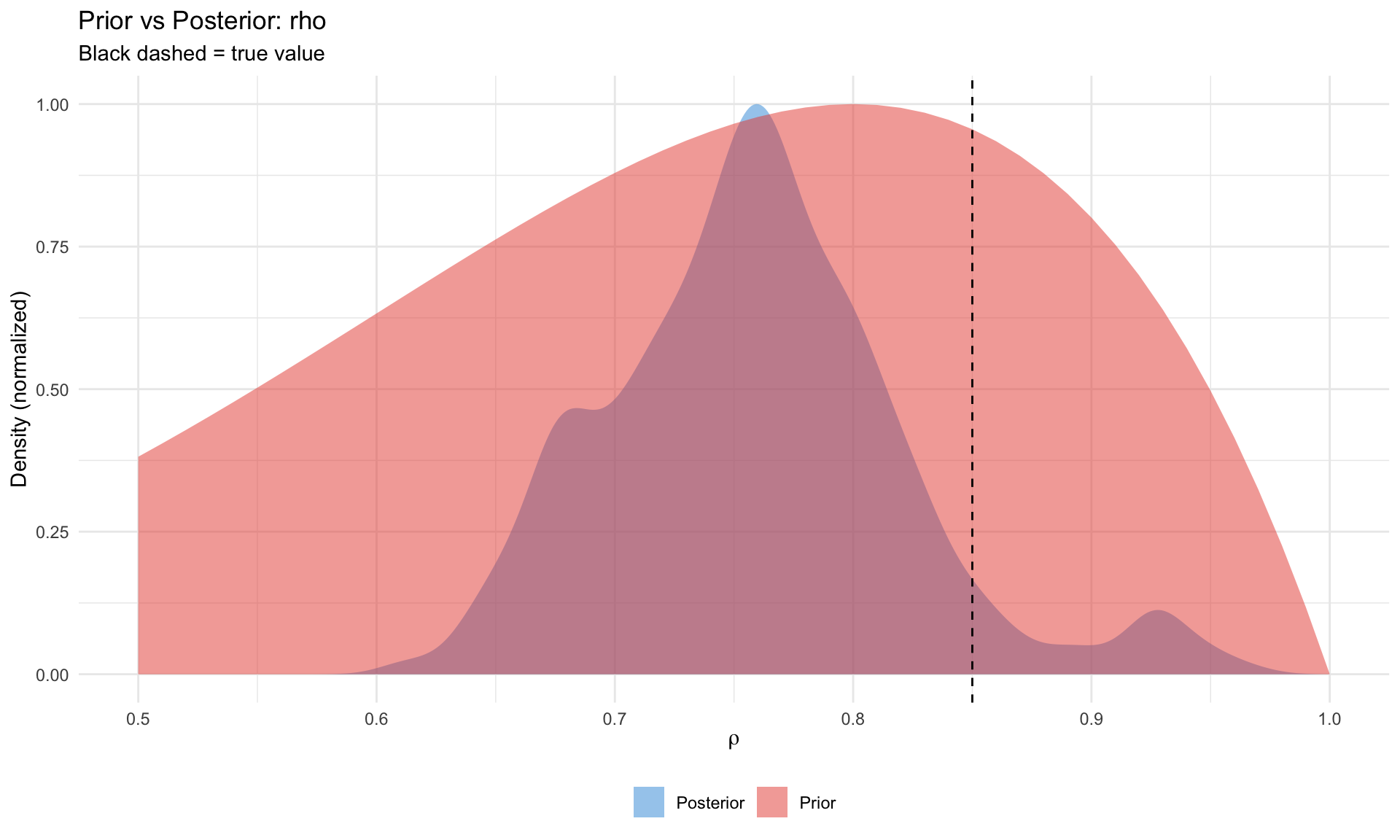
Prior vs Posterior
A key diagnostic: did the data inform the parameter?
| Pattern | Interpretation |
|---|---|
| Posterior ≠ Prior | Data is informative |
| Posterior ≈ Prior | Weak identification or uninformative data |
| Posterior outside prior support | Prior may be misspecified |
Identification
Local identification: Can different \(\theta\) values produce the same observables?
Dynare’s identification command checks: 1. Rank of the Jacobian at the mode 2. Which parameters are weakly identified
Symptoms of weak identification: - Flat likelihood surface - Prior ≈ Posterior - High posterior correlation between parameters
Summary
| Concept | Key Insight |
|---|---|
| State space | DSGE solution → transition + observation equations |
| Kalman filter | Recursive likelihood via prediction + update |
| Maximum likelihood | Point estimate, fast but no uncertainty |
| Bayesian | Full posterior, regularization, model comparison |
| Metropolis-Hastings | Sample from posterior via accept/reject |
| Marginal likelihood | Integrate out parameters for model comparison |
| Diagnostics | Check convergence, identification, prior vs posterior |
TipPractical Workflow
- Start with ML mode to find a good starting point
- Check identification before running full MCMC
- Run short chains first to tune
mh_jscale - Multiple chains for convergence diagnostics
- Compare prior/posterior to assess informativeness
- Model comparison only with converged chains
Key References
Estimation
- An & Schorfheide (2007) “Bayesian Analysis of DSGE Models” Econometric Reviews — Standard reference
- Herbst & Schorfheide (2016) Bayesian Estimation of DSGE Models — Modern textbook
- Del Negro & Schorfheide (2011) “Bayesian Macroeconometrics” Handbook — Survey chapter
Kalman Filter
- Hamilton (1994) Time Series Analysis Ch. 13 — Classic treatment
- Durbin & Koopman (2012) Time Series Analysis by State Space Methods — Comprehensive
MCMC
- Chib & Greenberg (1995) “Understanding the Metropolis-Hastings Algorithm” American Statistician
- Geweke (1999) “Using Simulation Methods for Bayesian Econometric Models” — Practical guide
Model Comparison
- Geweke (1999) “Bayesian Analysis of the Multinomial Probit Model” — Marginal likelihood computation
- Del Negro & Schorfheide (2004) “Priors from General Equilibrium Models for VARs” — DSGE-VAR
Software
- Adjemian et al. “Dynare” — Standard solver/estimator
- Herbst & Schorfheide companion — MATLAB/Python code