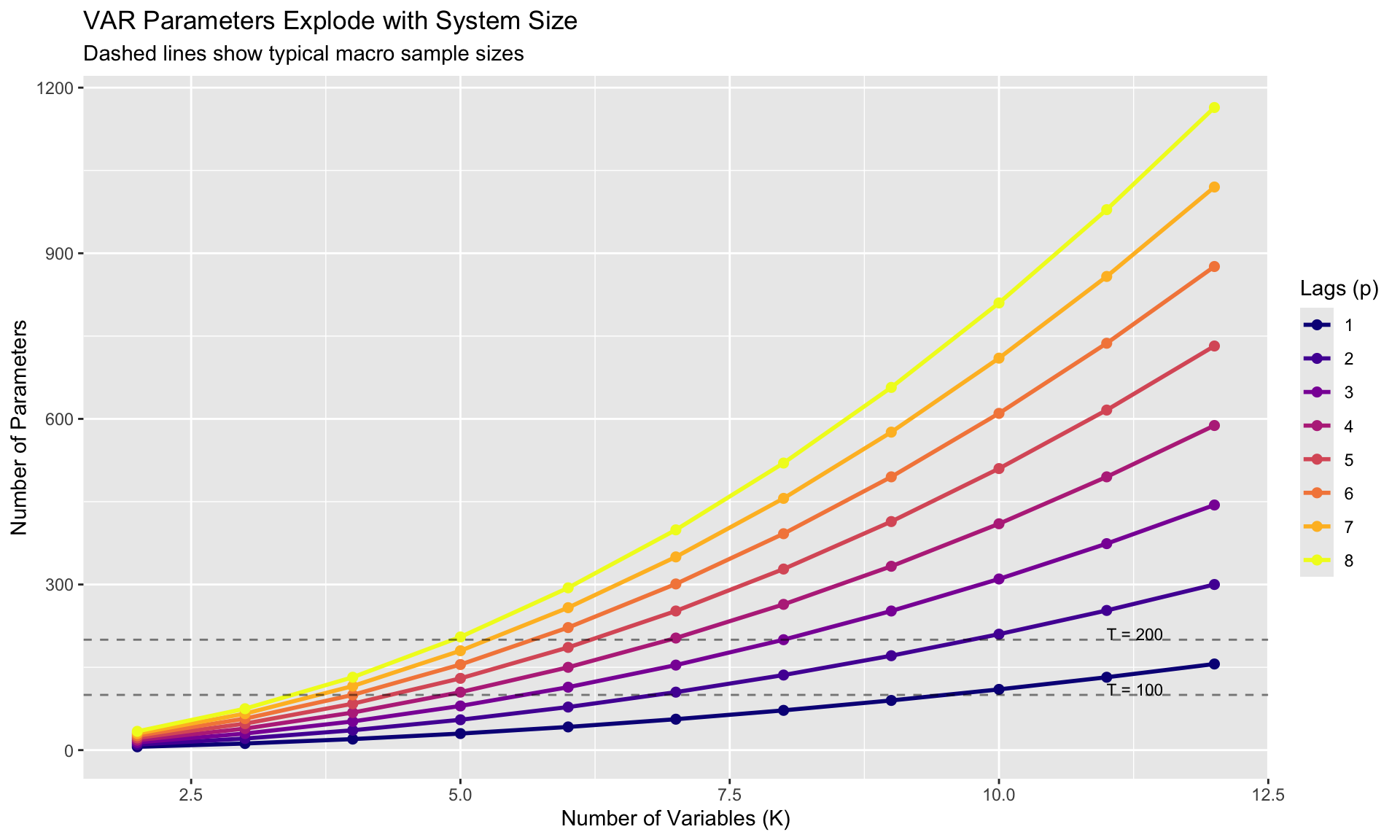
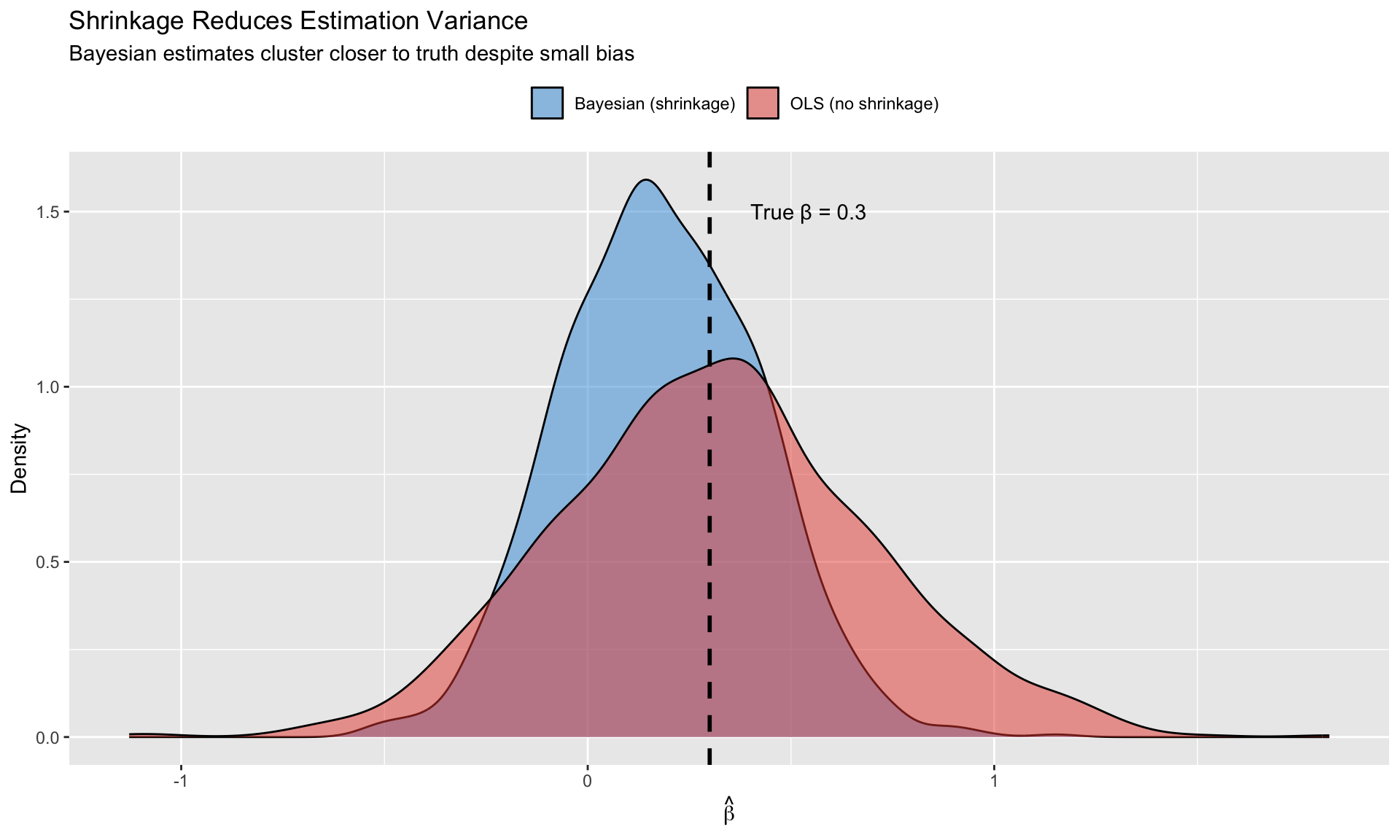
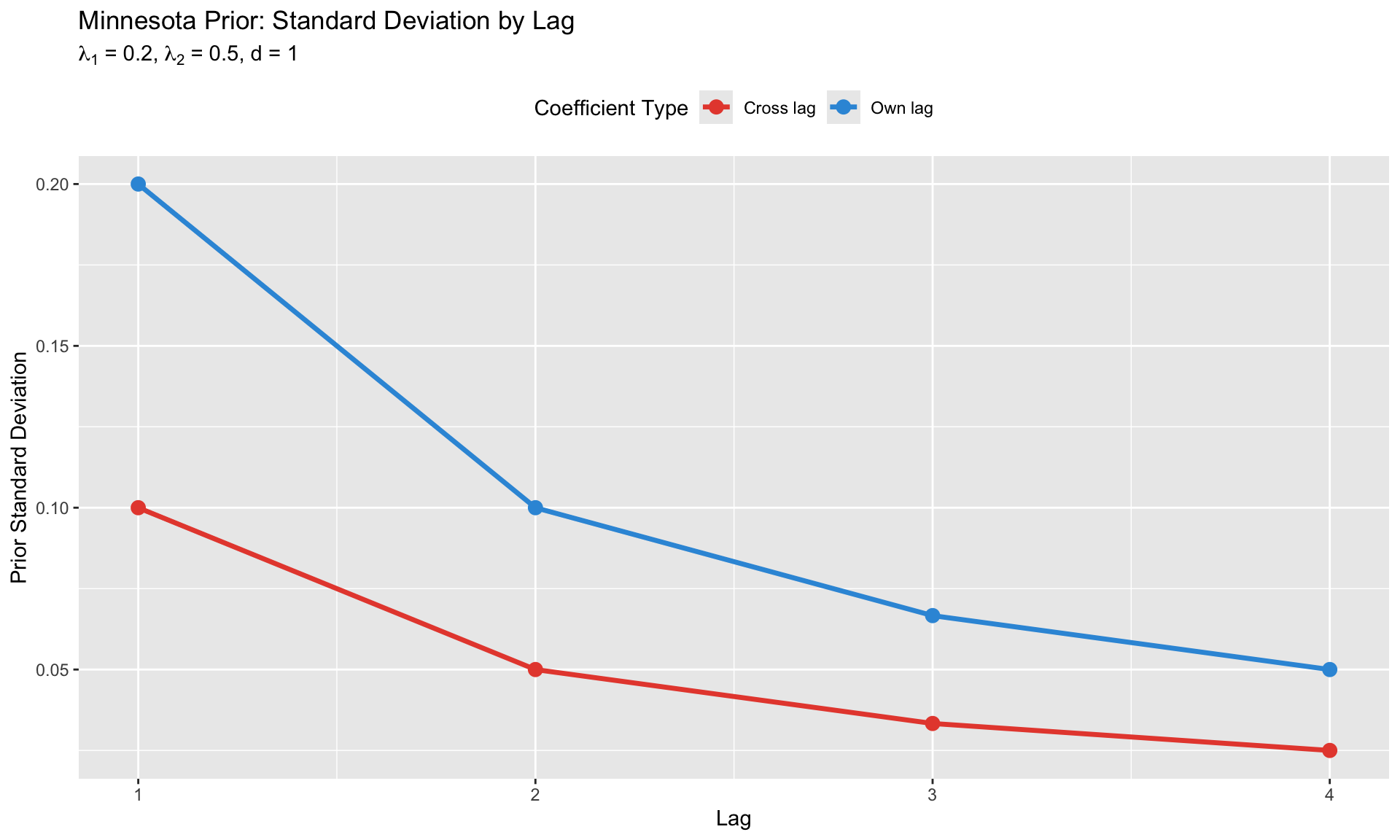
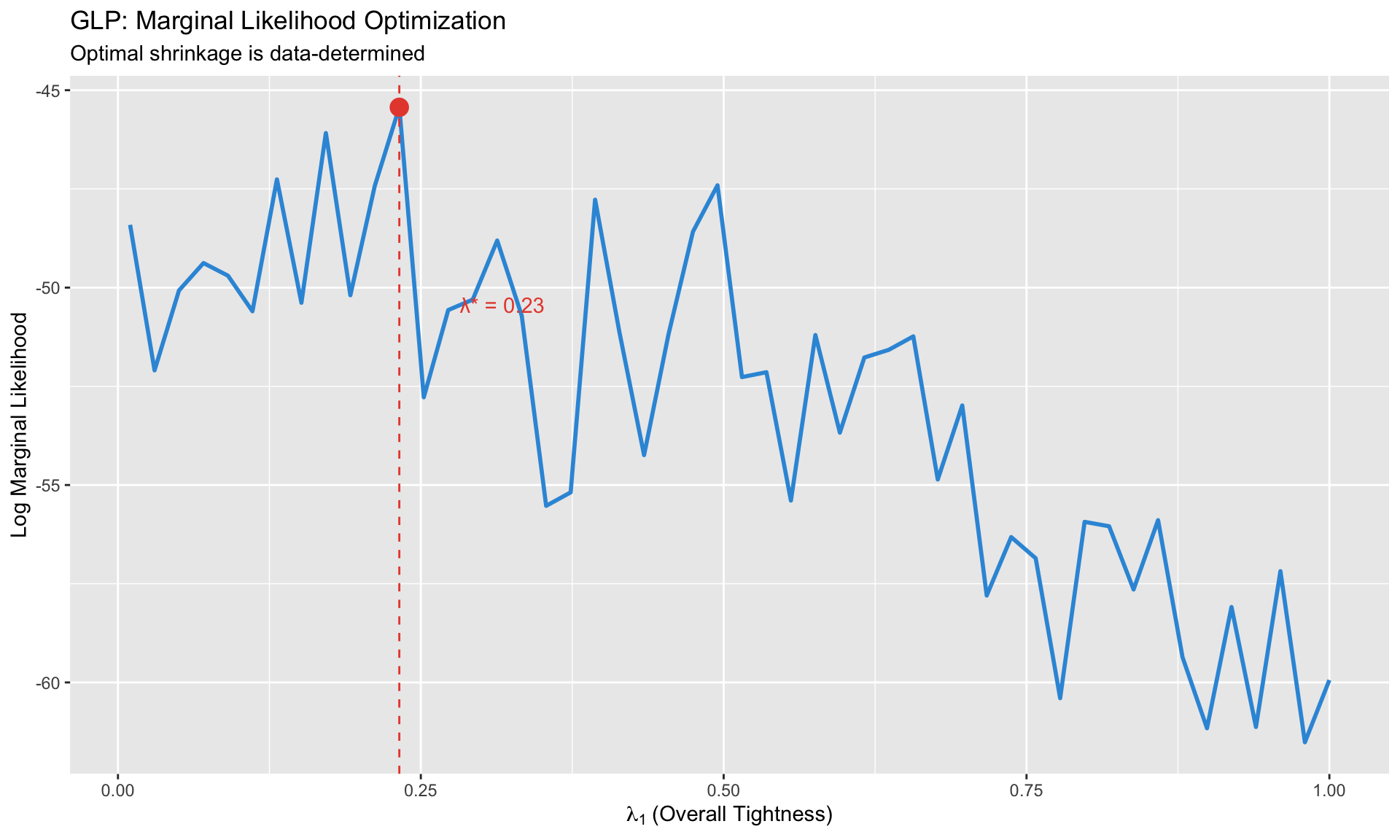
# Simplified BVAR Gibbs sampler demonstration
# Generate synthetic VAR(1) data
T_obs <- 100
K <- 2
# True parameters
A_true <- matrix(c(0.8, 0.1, 0.05, 0.7), K, K)
Sigma_true <- matrix(c(1, 0.3, 0.3, 1), K, K)
# Generate data
Y <- matrix(0, T_obs, K)
Y[1, ] <- rnorm(K)
for (t in 2:T_obs) {
Y[t, ] <- Y[t-1, ] %*% t(A_true) + rmvnorm(1, sigma = Sigma_true)
}
# Build matrices
y <- Y[2:T_obs, ]
X <- cbind(1, Y[1:(T_obs-1), ])
T_eff <- nrow(y)
M <- ncol(X)
# Minnesota-style prior
B0 <- matrix(0, M, K)
B0[2:3, ] <- diag(K) * 0.9 # Prior: close to random walk
# Prior precision (diagonal, tight) - must be (M*K) x (M*K) for vec(B)
lambda1 <- 0.2
# Build prior variance for each coefficient in vec(B)
# Structure: [const_eq1, y1_eq1, y2_eq1, const_eq2, y1_eq2, y2_eq2]
v0_diag <- numeric(M * K)
for (eq in 1:K) {
idx_const <- (eq - 1) * M + 1
v0_diag[idx_const] <- 100 # Loose prior on constant
for (var in 1:K) {
idx_var <- (eq - 1) * M + 1 + var
v0_diag[idx_var] <- lambda1^2 # Tight prior on AR coefficients
}
}
V0_inv <- diag(1 / v0_diag)
# Prior for Sigma
nu0 <- K + 2
S0 <- diag(K)
# Gibbs sampler
n_draw <- 2000
n_burn <- 500
B_draws <- array(0, dim = c(M, K, n_draw))
Sigma_draws <- array(0, dim = c(K, K, n_draw))
# Initialize
B_curr <- solve(crossprod(X)) %*% crossprod(X, y)
Sigma_curr <- crossprod(y - X %*% B_curr) / T_eff
for (g in 1:(n_draw + n_burn)) {
# Draw B | Sigma using vectorized form
# vec(B) | Sigma ~ N(b_post, V_post) where V_post = (V0_inv + Sigma^{-1} ⊗ X'X)^{-1}
Sigma_inv <- solve(Sigma_curr)
V_post_inv <- V0_inv + kronecker(Sigma_inv, crossprod(X))
V_post <- solve(V_post_inv)
b_post <- V_post %*% (V0_inv %*% as.vector(B0) +
kronecker(Sigma_inv, t(X)) %*% as.vector(y))
B_curr <- matrix(rmvnorm(1, b_post, V_post), M, K)
# Draw Sigma | B
U <- y - X %*% B_curr
S_post <- S0 + crossprod(U)
Sigma_curr <- solve(rWishart(1, nu0 + T_eff, solve(S_post))[,,1])
# Store
if (g > n_burn) {
B_draws[,,g - n_burn] <- B_curr
Sigma_draws[,,g - n_burn] <- Sigma_curr
}
}
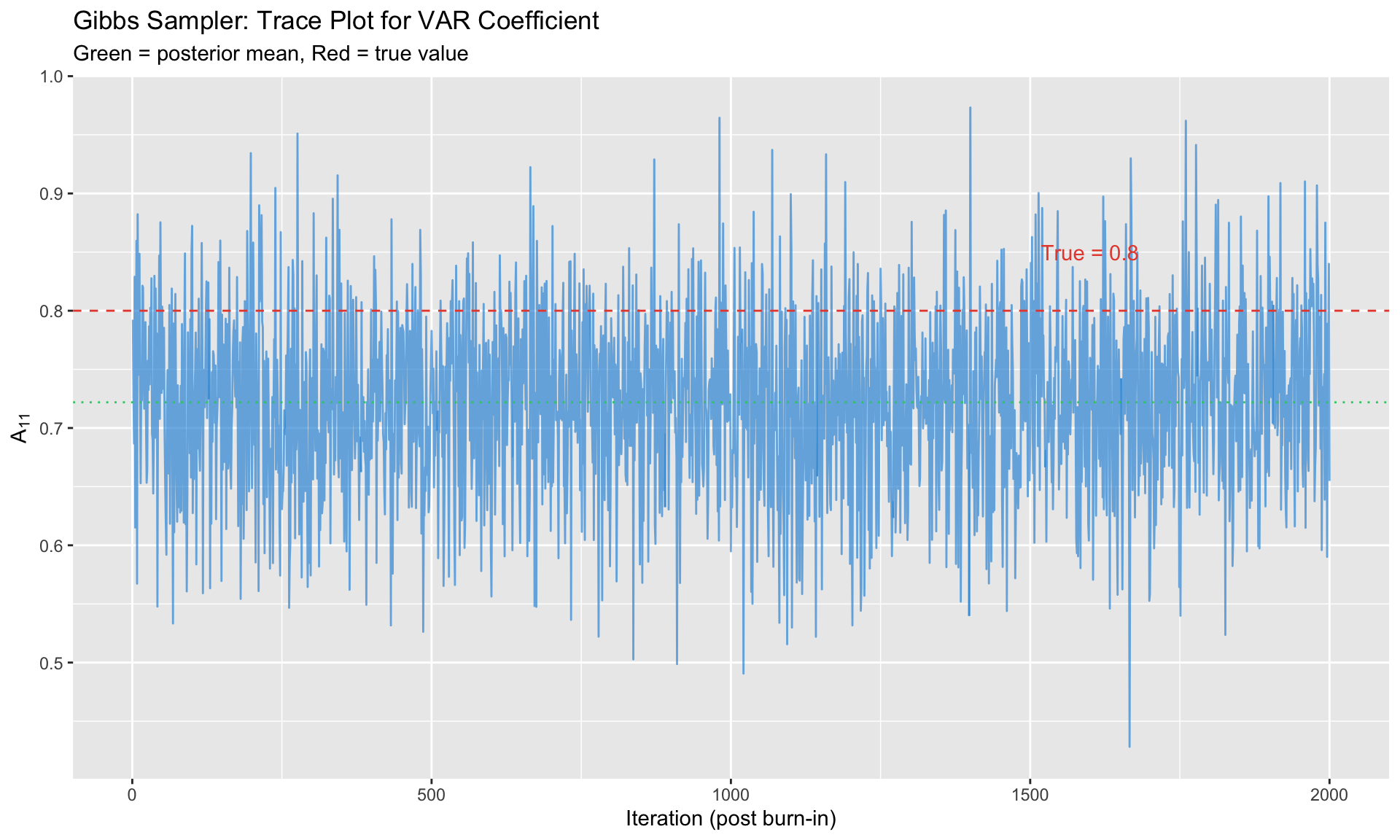
# Trace plot for A[1,1]
trace_df <- data.frame(
iteration = 1:n_draw,
value = B_draws[2, 1, ] # A[1,1] coefficient
)
ggplot(trace_df, aes(x = iteration, y = value)) +
geom_line(alpha = 0.7, color = "#3498db") +
geom_hline(yintercept = A_true[1,1], linetype = "dashed", color = "#e74c3c") +
geom_hline(yintercept = mean(trace_df$value), linetype = "dotted", color = "#2ecc71") +
annotate("text", x = n_draw * 0.8, y = A_true[1,1] + 0.05,
label = paste0("True = ", A_true[1,1]), color = "#e74c3c") +
labs(title = "Gibbs Sampler: Trace Plot for VAR Coefficient",
subtitle = "Green = posterior mean, Red = true value",
x = "Iteration (post burn-in)", y = expression(A[11]))